GPDB 差异化修复原理简介
Greenplum PR15146 增加了一种新的 mirror 节点修复方式 —— 差异化修复(Differential recovery),介于增量修复(Incremental recovery)和全量修复(Full recovery)之间,当数据量庞大且由于 WAL 缺失不能进行增量修复时,差异化修复提供了一种快速修复的能力。
☆ GPDB 节点修复原理简介
GPDB 的 segment 节点修复以 python 脚本 gprecoverseg 为入口,通过读取 Coordinator 节点的元数据,来获取需要修复(seg.isSegmentDown())节点的三元组(表示为 RecoveryTriplet):
- failed: 当前 down 的 segment,即要修复的节点
- live: 当前 up 的节点,作为修复的 source
- failover: 节点修复的 dest,如果该值为 None,则在 failed 节点原地修复
通过将如上三元组数组构造为一个 GpMirrorListToBuild,之后调用该对象的 recover_mirrors 函数进行修复。
该函数首先通过 build_recover_info 为每个需要修复的 segment 生成一个 RecoverInfo 对象,保存在一个 { hostname, RecoverInfo list } 的字典结构中。
def build_recovery_info(mirrors_to_build):
"""
This function is used to format recovery information to send to each segment host
@param mirrors_to_build: list of mirrors that need recovery
@return A dictionary with the following format:
Key = <host name>
Value = list of RecoveryInfos - one RecoveryInfo per segment on that host
"""
timestamp = datetime.datetime.today().strftime('%Y%m%d_%H%M%S')
recovery_info_by_host = defaultdict(list)
for to_recover in mirrors_to_build:
source_segment = to_recover.getLiveSegment()
target_segment = to_recover.getFailoverSegment() or to_recover.getFailedSegment()
process_name = 'pg_basebackup' if to_recover.isFullSynchronization() else 'pg_rewind'
progress_file = '{}/{}.{}.dbid{}.out'.format(gplog.get_logger_dir(), process_name, timestamp,
target_segment.getSegmentDbId())
hostname = target_segment.getSegmentHostName()
recovery_info_by_host[hostname].append(RecoveryInfo(
target_segment.getSegmentDataDirectory(), target_segment.getSegmentPort(),
target_segment.getSegmentDbId(), source_segment.getSegmentHostName(),
source_segment.getSegmentPort(), to_recover.isFullSynchronization(),
progress_file))
return recovery_info_by_host
然后调用 _run_setup_recovery 和 _run_recovery 分别去要修复的节点执行 gpsegsetuprecovery.py 和 gpsegrecovery.py。
gpsegsetuprecovery.py 在目标节点上根据宕机节点的修复类型(full/incremental)做不同的前置工作:
- 如果是全量修复,执行
ValidationForFullRecovery检测目标端的目录是否满足需求(如果非 overwrite 需要保证目标目录为空) - 如果是增量修复,执行
SetupForIncrementalRecovery去源端执行CHECKPOINT命令(执行 CHECKPOINT 是为了保证如果 source 端刚被 promote,其 control file 能反应最新的 timeline information,详见 pg_rewind)并将目的端的 postmaster.pid 删除。
gpsegrecovery.py 在目标节点上根据修复类型执行 pg_basebackup 或 pg_rewind,各命令使用的参数如下:
PgBaseBackup
| 参数 | 含义 |
|---|---|
| -c fast | Sets checkpoint mode to fast |
| -D target_datadir | 目标目录 |
| -h source_host | 源端目录 |
| -p source_port | 源端 port |
| –create-slot | 进行 backup 之间创建 –slot 指定的 replication slot |
| –slot | 要创建的 replcation slot 名称 |
| –wal-method stream | basebackup 忽略 WAL 文件的传输,而是由另外一个进程在 basebackup 的同时流式传输 WAL 文件 |
| –no-verify-checksums | 忽略 checksums |
| –write-recovery-conf | 生成 Recovery Config,PG 12 之前为 recovery.conf,之后为 postgresql.auto.conf |
| –force-overwrite | gpdb 引入的一个选项,在做 pg_basebackup 之前不需要目的端目录为空,而是在执行的过程中将需要从源端拷贝的目录或文件删除 |
| –target-gp-dbid | gpdb 引入的选项,为了适配 Greenplum 用户定义的 tablespaces |
| -E ./db_dumps -E ./promote | 忽略的目录 |
| –progress | 显示进度百分比 |
| –verbose | 显示更多的日志信息 |
PgRewind
| 参数 | 含义 |
|---|---|
| –write-recovery-conf | 生成 Recovery Config,PG 12 之前为 recovery.conf,之后为 postgresql.auto.conf |
| –slot=internal_wal_replication_slot | 写入 Recovery Config 的 replication slot |
| –source-server=CONNSTR | 源端数据库 |
| –target-pgdata=DIRECTORY | 目的端数据目录 |
| –progress | 显示更多的日志信息 |
值得注意的是,无论增量修复还是全量修复后,静态的实例状态未必处于一致的状态,都需要启动实例进入 recovery mode 回放日志来达到一致的状态。主要原因有两个:
- 有些文件在拷贝过之后在源端有修改,这就使得数据目录不是一个完整的快照状态
- 读取的文件可能不是完整的数据页(由于 pg 的 PAGE_SIZE 和 OS 的 PAGE_SIZE 不同),需要源端开启 full_page_writes 选项保证正确修复
关于 postgres 全量修复和增量修复更详细的解读可参考 pg_basebackup 代码浅析 和 pg_rewind 代码浅析。
☆ 差异化修复
gpdb 作为分析型数据库通常实例的数据量较大,在宕机之后如果能增量修复具有显著的性能优势,但有时由于 WAL 日志缺失会导致增量修复的失败,且如果 pg_rewind 中断了,不建议进行重试,只能使用更耗时的全量修复。在全量修复过程中如果网络抖动,极有可能在同步了 90% 数据的时候修复失败,只能重新执行全量修复,费力劳心。
因此社区提出了使用 rsync 进行增量修复的方案,在数据量大且修改较少的情况下,rsync 的算法(Rolling checksum & Checksum searching)能够极大减少数据传输量,且支持断点续传。并且 rsync 已经是 gpdb 本地升级失败回退工作的依赖工具,无需额外安装。
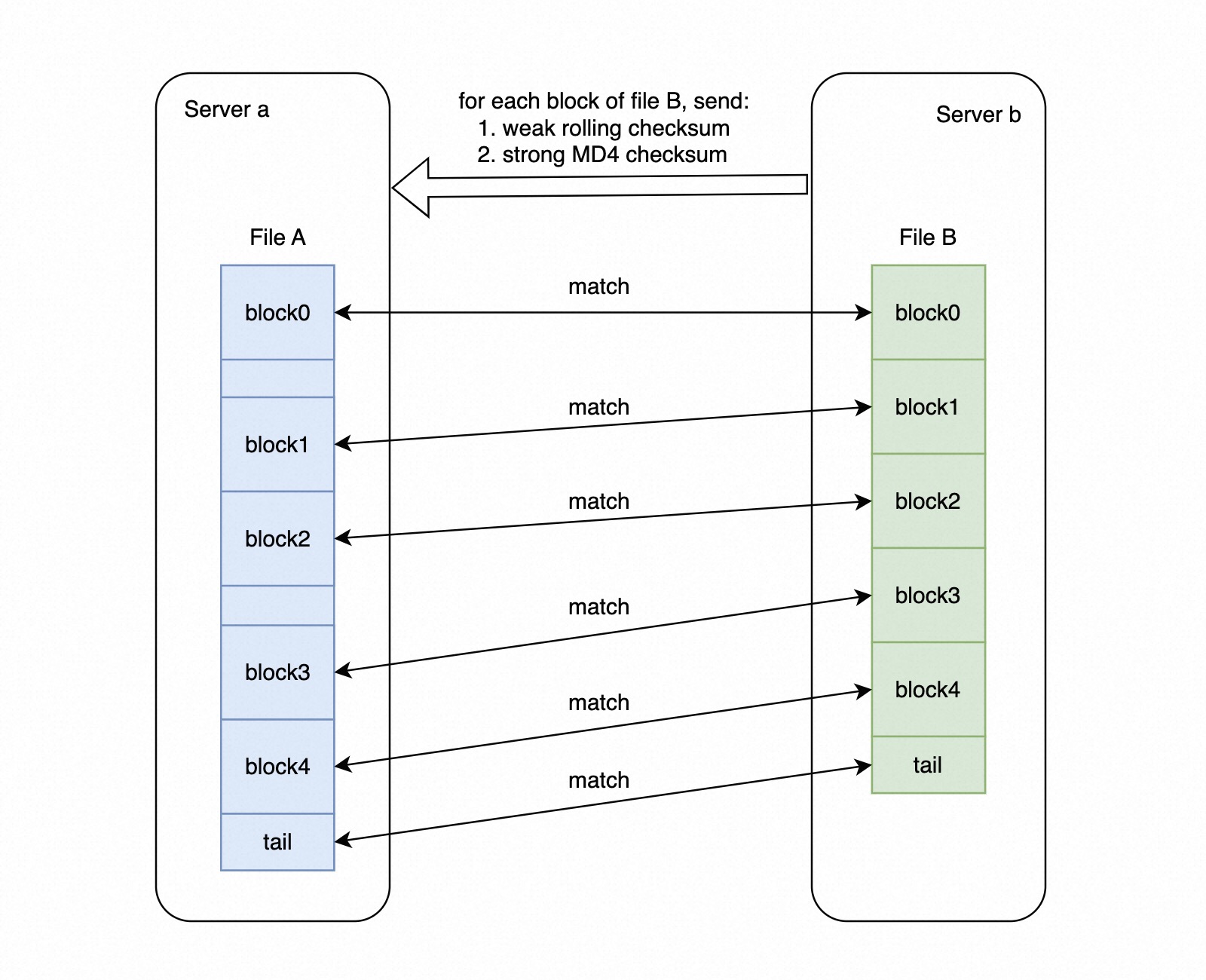
简述一下上图中对一个文件进行传输的过程,Server A 为 source,Server b 为 target,即算法完成后 Server b 上的文件 B 变为 Server a 的文件 A:
- 对文件 B 以 block 级别分别计算一个较弱的 rolling checksum 和一个强的 MD4 checksum 传输到 source 端
- Server a 在收到这些 checksum 之后,按 rolling checksum 的高 16 位创建一个 2^16 个 bucket 的 hash table,checksum 的低 16 位 按照链表的方式存储在对应的 bucket 中
- 对文件 A 按照每次偏移一个字节的方式去计算一个 block 的 rolling checksum,然后上述的 hash table 查找是否有 match 的 block,如果匹配,则进一步搜索 MD4 checksum
- 如果强 checksum 也能找到匹配,认为这个 block 在 target 端存在,此时把上次匹配 block 的 end 和本次匹配 block 的 offset 以及 target 端对应的 block index 发送到 target,target 根据这些信息将该内容写入文件 B 对应的位置
- 对于匹配的 block,下次计算直接从 block 的结尾开始计算,这可以在两个文件几乎相同的情况下节省大量的计算
差异化修复算法
差异化修复的逻辑和 pg_basebackup 非常相似,其算法步骤:
- On source: Skip differential recovery if the segment is already in backup
- On source: drop the replication slot if exists
- On source: start backup: pg_start_backup(‘differential_backup’)
- On source: create a replication slot
- On target: sync pg_data of the mirror with its primary using rsync
- On target: sync table space created outside the data directory
- On source: stop backup: pg_stop_backup()
- On target: write configuration file: pg_basebackup -D
--write-conf-files-only - On target: sync wal and pg_control file
- On target: update port in the configuration
- On target: start segment
- On Source: if any exception is raised during steps 2 to 11 the program should stop the backup
pg_basebackup 使用两个进程对数据和 WAL 分别拉取,在发送 BASE_BACKUP 命令之后、fork LogStreamer 之前创建了 physical replication slot,上述的步骤 3-8 对应 pg_basebackup 的 BaseBackup 逻辑,步骤 9 中的 sync wal 对应 pg_basebackup 的 LogStreamerMain 逻辑,pg_basebackup 使用 perform_base_backup 发送完所有 tablespaces 和 DataDir 中的数据后再发送 pg_control 文件,差异化修复则是在发送完 WAL 文件后再同步 pg_control,不影响正确性。步骤 10-11 是 gpsegrecovery 不同修复类型共有的启动逻辑。
代码的主要逻辑是在 gpsegrecovery.py 添加了一个 DifferentialRecovery 类,该类的 run 方法实现了上述算法:
def run(self):
self.logger.info("Running differential recovery with progress output temporarily in {}".format(
self.recovery_info.progress_file))
self.error_type = RecoveryErrorType.DIFFERENTIAL_ERROR
""" Drop replication slot 'internal_wal_replication_slot' """
if self.replication_slot.slot_exists() and not self.replication_slot.drop_slot():
raise Exception("Failed to drop replication slot")
""" start backup with label differential_backup """
self.pg_start_backup()
try:
if not self.replication_slot.create_slot():
raise Exception("Failed to create replication slot")
""" rsync pg_data and tablespace directories including all the WAL files """
self.sync_pg_data()
""" rsync tablespace directories which are out of pg-data-directory """
self.sync_tablespaces()
finally:
# Backup is completed, now run pg_stop_backup which will also remove backup_label file from
# primary data_dir
if is_seg_in_backup_mode(self.recovery_info.source_hostname, self.recovery_info.source_port):
self.pg_stop_backup()
""" Write the postresql.auto.conf and internal.auto.conf files """
self.write_conf_files()
""" sync pg_wal directory and pg_control file just before starting the segment """
self.sync_wals_and_control_file()
self.logger.info(
"Successfully ran differential recovery for dbid {}".format(self.recovery_info.target_segment_dbid))
""" Updating port number on conf after recovery """
self.error_type = RecoveryErrorType.UPDATE_ERROR
update_port_in_conf(self.recovery_info, self.logger)
self.error_type = RecoveryErrorType.START_ERROR
start_segment(self.recovery_info, self.logger, self.era)
其中:
sync_pg_data、sync_tablespaces、sync_wals_and_control_file用 Rsync 传输数据write_conf_files使用PgBaseBackup新增的 writeconffilesonly 选项生成recover.conf文件update_port_in_conf、start_segment是同步之后的重启逻辑,与增量修复和全量修复相同
Rsync 使用的参数:
| 参数 | 含义 |
|---|---|
| -r | 递归同步目录下的目录和文件 |
| -v | 显示更多信息 |
| -a | archive mode; same as -rlptgoD |
| -c | 使用 checksum 进行文件对比而 mod-time 和 size |
| –progress | 显示进度 |
| –delete | 删除目标端多于的文件 |
| –exclude | 忽略的文件或目录,如 pg_log |
| SRC | 源端目录 |
| DEST | 目的端目录 |
☆ 性能测试
测试使用的实例是阿里云 ECS,规格为 ecs.c5.2xlarge。
| 参数 | 配置 |
|---|---|
| CPU | Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz, 8 vCPU |
| Cache Size | 33792 KB |
| Memory | 16 GiB |
| OS | Ubuntu 20.04 64bit UEFI |
| Disk | ESSD PL0 500GiB (7800 IOPS) |
测试步骤(部分操作详见附录):
- 部署 gpdb demo 集群,2 primary & 2 mirror
- 生成 tpch SF = 100 数据
- 建表(这里使用行存表)并导入数据,导入后每个 datadir 数据量约 65G
- 停掉其中一个 mirror 节点并等待 fts 将其标记 down
- truncate supplier 后重新导入,模拟写入数据
- 分别执行 gprecoverseg -a/gprecoverseg -aF/gprecoverseg -a –differential 并计时
各个命令使用时长:
| 恢复命令 | 恢复时长 |
|---|---|
| incremental | 0.32s user 0.07s system 5% cpu 6.507 total |
| differential | 6.76s user 3.04s system 1% cpu 12:56.93 total |
| full | 5.52s user 2.57s system 1% cpu 12:20.77 total |
出乎意料的是,差异化修复在 65G 数据量的场景下性能略逊于全量修复,分析主要有以下几点原因:
- rsync 接收 incremental file list 占用了很长时间
- 单机部署多节点数据传输走的 LOOPBACK 网络,平均传输速度 750Mb/s(iftop),峰值 1.4Gb/s,而磁盘吞吐 160MB/s,瓶颈为磁盘而非网络
- 差异化存储虽然减少了写IO,但相较于全量修复,多了 checksum 计算和搜索的开销
☆ 使用场景
通过上述的实验发现,当网络非瓶颈时,差异化修复和全量修复性能相当,差异化修复更适合在网络较差的场景下使用。
附录
生成 tpch100G 数据
git clone https://github.com/electrum/tpch-dbgen.git
cd tpch-dbgen
echo "#define EOL_HANDLING 1" >> config.h # 行末不加 '|'
make -j8
for i in {1..8}; do ./dbgen -s 100 -S $i -C 8 -f &; done
mv *.tbl.* /home/gpdb/tpch100G
mv *.tbl /home/gpdb/tpch100G
启动 gpfdist
gpfdist -d /home/gpdb/tpch100G -p 8081 -l /home/gpdb/gpAdminLogs/gpfdist.log &
建表&导入数据命令
create schema IF NOT EXISTS tpch100g;
set search_path = tpch100g;
CREATE TABLE customer (
c_custkey integer NOT NULL,
c_name character varying(25) NOT NULL,
c_address character varying(40) NOT NULL,
c_nationkey integer NOT NULL,
c_phone character(15) NOT NULL,
c_acctbal numeric(15,2) NOT NULL,
c_mktsegment character(10) NOT NULL,
c_comment character varying(117) NOT NULL
)
distributed by (c_custkey);
CREATE TABLE lineitem (
l_orderkey bigint NOT NULL,
l_partkey integer NOT NULL,
l_suppkey integer NOT NULL,
l_linenumber integer NOT NULL,
l_quantity numeric(15,2) NOT NULL,
l_extendedprice numeric(15,2) NOT NULL,
l_discount numeric(15,2) NOT NULL,
l_tax numeric(15,2) NOT NULL,
l_returnflag character(1) NOT NULL,
l_linestatus character(1) NOT NULL,
l_shipdate date NOT NULL,
l_commitdate date NOT NULL,
l_receiptdate date NOT NULL,
l_shipinstruct character(25) NOT NULL,
l_shipmode char(10) NOT NULL,
l_comment varchar(44) NOT NULL
)
distributed by (l_orderkey);
CREATE TABLE nation (
n_nationkey integer NOT NULL,
n_name character(25) NOT NULL,
n_regionkey integer NOT NULL,
n_comment character varying(152)
)
distributed by (n_nationkey);
CREATE TABLE orders (
o_orderkey bigint NOT NULL,
o_custkey integer NOT NULL,
o_orderstatus character(1) NOT NULL,
o_totalprice numeric(15,2) NOT NULL,
o_orderdate date NOT NULL,
o_orderpriority character(15) NOT NULL,
o_clerk character(15) NOT NULL,
o_shippriority integer NOT NULL,
o_comment character varying(79) NOT NULL
)
distributed by (o_orderkey);
CREATE TABLE part (
p_partkey integer NOT NULL,
p_name character varying(55) NOT NULL,
p_mfgr character(25) NOT NULL,
p_brand character(10) NOT NULL,
p_type character varying(25) NOT NULL,
p_size integer NOT NULL,
p_container character(10) NOT NULL,
p_retailprice numeric(15,2) NOT NULL,
p_comment character varying(23) NOT NULL
)
distributed by (p_partkey);
CREATE TABLE partsupp (
ps_partkey integer NOT NULL,
ps_suppkey integer NOT NULL,
ps_availqty integer NOT NULL,
ps_supplycost numeric(15,2) NOT NULL,
ps_comment character varying(199) NOT NULL
)
distributed by (ps_partkey);
CREATE TABLE region (
r_regionkey integer NOT NULL,
r_name character(25) NOT NULL,
r_comment character varying(152)
)
distributed by (r_regionkey);
CREATE TABLE supplier (
s_suppkey integer NOT NULL,
s_name character(25) NOT NULL,
s_address character varying(40) NOT NULL,
s_nationkey integer NOT NULL,
s_phone character(15) NOT NULL,
s_acctbal numeric(15,2) NOT NULL,
s_comment character varying(101) NOT NULL
)
distributed by (s_suppkey);
CREATE EXTERNAL TABLE customer_ext (like customer)
LOCATION ('gpfdist://localhost:8081/customer.tbl.*')
FORMAT 'TEXT' (DELIMITER '|')
LOG ERRORS SEGMENT REJECT LIMIT 10;
CREATE EXTERNAL TABLE lineitem_ext (like lineitem)
LOCATION ('gpfdist://localhost:8081/lineitem.tbl.*')
FORMAT 'TEXT' (DELIMITER '|')
LOG ERRORS SEGMENT REJECT LIMIT 10;
CREATE EXTERNAL table nation_ext(like nation)
LOCATION ('gpfdist://localhost:8081/nation.tbl')
FORMAT 'TEXT' (DELIMITER '|')
LOG ERRORS SEGMENT REJECT LIMIT 10;
CREATE EXTERNAL TABLE orders_ext(like orders)
LOCATION ('gpfdist://localhost:8081/orders.tbl.*')
FORMAT 'TEXT' (DELIMITER '|')
LOG ERRORS SEGMENT REJECT LIMIT 10;
CREATE EXTERNAL TABLE part_ext (like part)
LOCATION ('gpfdist://localhost:8081/part.tbl.*')
FORMAT 'TEXT' (DELIMITER '|')
LOG ERRORS SEGMENT REJECT LIMIT 10;
CREATE EXTERNAL TABLE partsupp_ext (like partsupp)
LOCATION ('gpfdist://localhost:8081/partsupp.tbl.*')
FORMAT 'TEXT' (DELIMITER '|')
LOG ERRORS SEGMENT REJECT LIMIT 10;
CREATE EXTERNAL TABLE region_ext (like region)
LOCATION ('gpfdist://localhost:8081/region.tbl')
FORMAT 'TEXT' (DELIMITER '|')
LOG ERRORS SEGMENT REJECT LIMIT 10;
CREATE EXTERNAL TABLE supplier_ext (like supplier)
LOCATION ('gpfdist://localhost:8081/supplier.tbl.*')
FORMAT 'TEXT' (DELIMITER '|')
LOG ERRORS SEGMENT REJECT LIMIT 10;
insert into customer select * from customer_ext;
insert into lineitem select * from lineitem_ext;
insert into nation select * from nation_ext;
insert into orders select * from orders_ext;
insert into part select * from part_ext;
insert into partsupp select * from partsupp_ext;
insert into region select * from region_ext;
insert into supplier select * from supplier_ext;
analyze customer;
analyze lineitem;
analyze nation;
analyze orders;
analyze part;
analyze partsupp;
analyze region;
analyze supplier;