Kubernetes学习备忘
本文记录从2016.8.15日开始到2016.8.19日学习Kubernetes的要点和心得,希望通过一周的学习,能对Kubernetes 有一个大致的了解。
Kubernetes是什么
Kubernetes是Google开源的容器集群管理系统。它构建在Docker技术之上,为容器化的应用提供资源调度、部署运行、 服务发现、扩容缩容等一整套功能。Google从2004年开始使用容器技术,于2006年发布Cgroup,Google内部开发的集 群资源管理平台Borg和Omega广泛使用在Google的各个基础设施中,Kubernetes的灵感来源于Borg系统,更是吸收了 包括Omega在内的容器管理器的经验和教训。
Kubernetes,在古希腊语中是舵手的意思,它利用Google在容器技术上的实践经验和技术积累,同时吸收了Docker社 区的最佳实践,已经成为云计算服务的舵手。
Kubernetes有以下优秀特性:
-
强大的容器编排能力: Kubernetes深度集成了Docker,天然适应容器的特点,设计出强大的容器编排能力,比 如容器组合、标签选择和服务发现等,可以满足企业级需求。
-
轻量级: Kubernetes遵循微服务架构,整个系统划分出各个功能独立的组件,组件之间边界清晰,部署简单, 可以轻易地运行在各种系统和环境中。同时,Kubernetes中的许多功能都实现了插件化,可以非常方便地进行扩展 和替换。
-
可移植: 适用于公有云、私有云、混合云以及多重云
-
可扩展: Kubernetes支持模块化、插件化、钩子化及可编排
-
自愈: 自动定位、自动重启、自动创建副本
Kubernetes基本概念:
-
Cluster(集群): 一个集群由一组物理机、虚拟机及其他基础架构资源构成,这些资源被Kubernetes 用来跑你的应用程序。
-
Node(节点): 运行Kubernetes的物理机或虚拟机,在节点之上可以调度Pods。Pod最终运行在Node上, Node可以认为是Pod的宿主机。
-
Pod: Pod是若干共享卷的一组应用容器的组合。Pod是最小的部署单元(而非容器),可以使用Kubernetes 创建、调度并管理Pod。Pods可以被单独地创建,但比较好的方式是用replication controller来创建Pod。Pod通 过提供更高层次的抽象,提供了更加灵活的部署和管理模式。
-
Replication controller: Replication controller管理Pods的生命周期,它通过 创建或杀死Pod保证在任何时间都有指定数目的pods在运行,Replication controller是弹性伸缩、滚动升级的实 现核心。
-
Service(服务): 为一组Pods提供单一、稳定的名字和地址。它是真实应用服务的抽象,定义了Pod 的逻辑集合和访问这个Pod集合的策略。Service将代理Pod对外表现为一个单一访问接口,外部不需要了解后端Pod 如何运行,这给扩展和维护带来很多好处,提供了一套简化的服务代理和发现机制。
-
Label(标签): 标签是用于区分Pod、Service、Replication controller的Key/Value对,实际上, Kubernetes中的任意API对象都可以通过Label进行标识。Label是Service和Replication Controller运行的基础, 它们都通过Label来关联Pod,相比于强绑定模型,这是一种很好的松耦合关系。
Kubernetes的架构和组件
Kubernetes遵循微服务架构理论,整个系统划分出各个功能独立的组件,组件之间边界清晰,部署简单,可以轻易 地运行在各种系统和环境中。
Kubernetes架构如图所示:
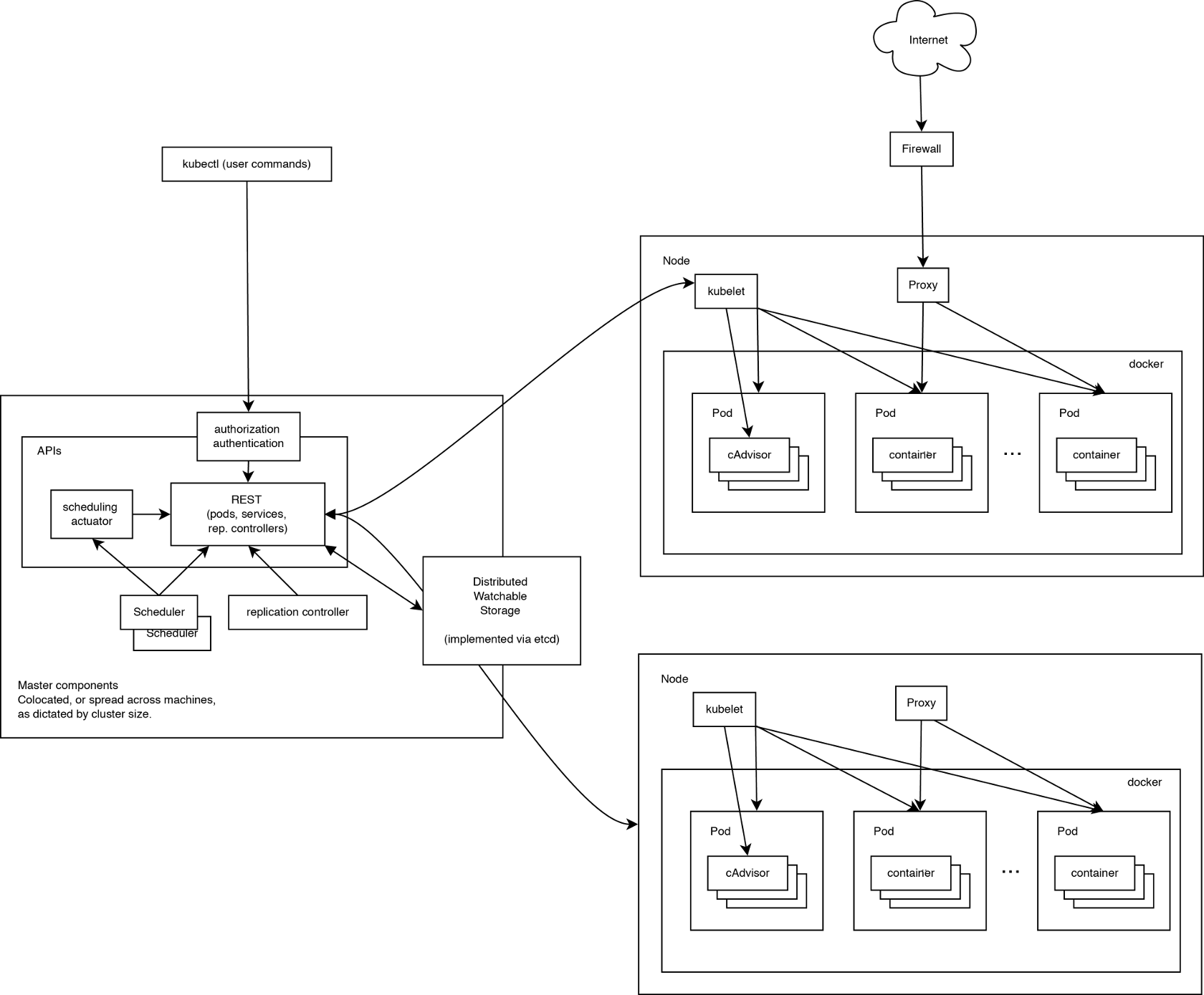
Kubernetes属于主从分布式架构,一个运行的Kubernetes集群包含node agents(kubelet)和master组件(APIs,
调度器等),使用Etcd作为存储中间件,Etcd是一个高可用的键值存储系统,通过Raft一致性算法处理日志复制以
保证强一致性。Kubernetes使用Etcd作为系统的配置存储中心,重要数据都是持久化在Etcd中的,这使得
Kubernetes架构的各个组件属于无状态,可以更简单地实施分布式集群部署。社区还在致力与将所有的组件都运行
在容器中,以使调度100%插件化。
Kubernetes Node
在学习Kubernetes系统架构的时候,我们将运行在worker node上的服务和构成集群控制层面的服务分别看待。 Kubernetes Node包含了运行应用容器的必要服务以及被master系统管理的服务,每个节点都运行Docker,Docker 负责下载镜像和运行容器的细节。
kubelet: 负责管理pods以及它们的容器、镜像、卷等。kubelet从Kubernetes API Server接收Pod的创建请求,
启动和停止容器,监控容器运行状态并汇报给Kubernetes API Server。
kube-proxy: 每个node都会运行一个简单的网络代理和负载均衡器。kube-proxy在每个节点映射了定义在
Kubernetes API中的服务,并根据服务信息创建代理网络,实现Service到Pod的请求路由和转发,从而实现
Kubernetes层级的虚拟转发网络(TCP和UDP流转发–round robin)。
docker: Kubernetes Node是容器运行节点,需要运行Docker服务,目前Kubernetes也支持Rocket,一款CoreOS
开发的类Docker的开源容器引擎。
Kubernetes Control Plane
Kubernetes Control Plane为一系列组件。目前它们都运行在一个单一的Master Node上,但是很快就会改变这种 现状以支持集群的高可用。这些组件相互配合来提供集群的统一视图。
etcd: 所有持久的master状态都存储在etcd实例。这是可靠地存储配置数据的一种非常好的方式。在watch的
支持下,各部件可以很快获取变化的通知。
Kubernetes API Server: 作为Kubernetes系统的入口,它提供一个CRUD-y服务器,将所有的业务逻辑实现在分
离的组件或插件中,处理REST操作,验证它们并更新etcd中对应的对象。
Scheduler: Scheduler通过/binding API将未调度的Pods绑定到相应的节点(即为新建的Pod分配机器)。
Scheduler是插件化的,意味着可以很方便地替换成其他调度器。
Kubernetes Controller Manager Server: 所有其它集群级别的功能现在都在Controller Manager中实现。目前
已经实现很多控制器来维护Kubernetes的健康状态,主要包含的控制器如下表所示:
| 控制器 | 说明 |
|---|---|
| Replication Controller | 关联Replication Controller和Pod,保证ReplicationController定义的副本数量与实际运行Pod的数量是一致的 |
| Node Controller | 定期检查Node的健康状态,标识出实效的Node |
| Namespace Controller | 定期清理无效的Namespace,包括Namespace下的API对象,如Pod、Service和Secret |
| Service Controller | 为Loadbalancer类型的Service创建管理负载均衡器 |
| Endpoints Controller | 关联Service和Pod,创建Endpoints作为Service的后端,当Pod发生变化时,实时刷新Endpoints |
| Service Account Controller | 为每个Namespace创建默认Service Account,同时为Service Account创建Service Account Secret |
| Persistent Volume Controller | 管理维护Persistent Volume和Persistent Volume Claim,为新的Persistent Volume Claim分配Persistent Volume进行绑定,为释放的Persistent执行清理回收 |
| Daemon Set Controller | 负责创建Daemon Pod,保证指定的Node上正常运行Daemon Pod |
| Deployment Controller | 关联Deployment和Replication Controller,保证运行指定数目的Pod。当Deployment更新时,控制实现Replication Controller和Pod的更新 |
| Job Controller | 为Job创建一次性任务Pod,保证完成Job指定的任务数目 |
| Pod Autoscaler Controller | 实现Pod的自动伸缩,定时获取监控数据,进行策略匹配,当满足条件时执行Pod的伸缩动作 |
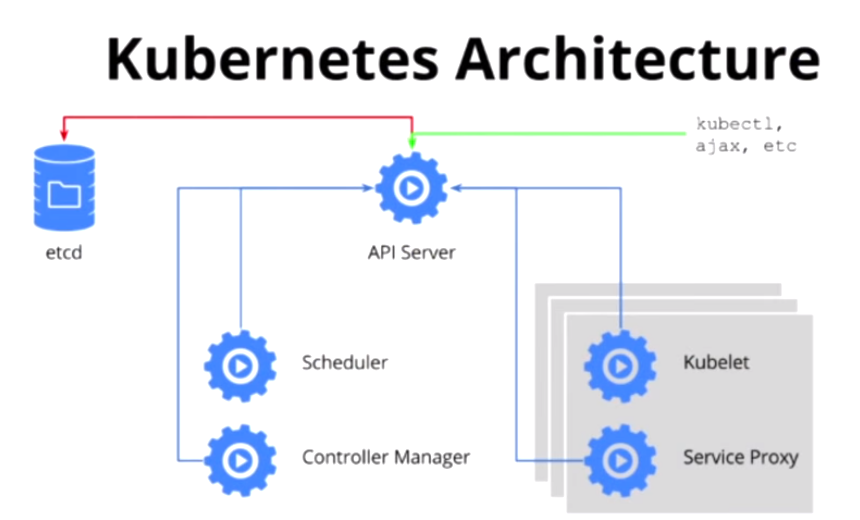
在CoreOS Fest 2015的A Technical Overview of Kubernetes中,Brendan Burns多次提到
解耦合这个概念。插件化是Kubernetes的一个主要思想,下面看另外一个Kubernetes的架构图来帮助理解。
Minikube安装
如果为了开发和测试,想在本地创建一个单点的Kubernetes集群,Minikube是一种推荐的方式,它打 包并配置了一个Linux VM,Docker以及所有的Kubernetes组件,并为本地部署进行了优化。Minikube支持k8s的如 下特性:
- DNS
- NodePorts
- ConfigMaps and Secrets
- Dashboards
Minikube现在还不能支持云提供商的部分特性:
- Loadbalancers
- PersistentVolumes
- Ingress
Minikube需要打开VT-x/AMD-v硬件虚拟化,查看是否打开运行如下命令:
$cat /proc/cpuinfo | grep 'vmx\|svm'安装最新的Virtualbox:
$cd /etc/yum.repos.d
$wget http://download.virtualbox.org/virtualbox/rpm/rhel/virtualbox.repo
$sudo yum update -y
$sudo yum --enablerepo=epel install dkms -y
$sudo yum groupinstall "Development Tools" -y
$sudo yum install kernel-devel -y
$sudo yum install VirtualBox-5.0.x86_64 -y下载minikube二进制文件并放置在系统可以调用的路径下:
$curl -Lo minikube https://storage.googleapis.com/minikube/releases/v0.7.1/minikube-linux-amd64 && chmod +x minikube && sudo mv minikube /usr/local/bin/下载kubectl二进制文件:
// linux/amd64 generic download path is:
// https://storage.googleapis.com/kubernetes-release/release/${K8S_VERSION}/bin/${GOOS}/${GOARCH}/${K8S_BINARY}
$curl -Lo kubectl http://storage.googleapis.com/kubernetes-release/release/v1.3.0/bin/linux/amd64/kubectl && chmod +x kubectl && sudo mv kubectl /usr/local/bin/启动Kubernetes单点集群,以下命令会启动一个轻量级的本地集群,包含一个master, etcd, Docker以及一个Node。
$yum install "kernel-devel-uname-r == $(uname -r)"
$sudo /sbin/rcvboxdrv setup
$minikube start
Starting local Kubernetes cluster...
Kubernetes is available at https://192.168.99.100:8443.
Kubectl is now configured to use the cluster.如下命令可以显示Kube-system Pods:
$kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system kube-addon-manager-minikubevm 1/1 Running 0 1h
kube-system kubernetes-dashboard-tava9 1/1 Running 0 1hminikube dashboard用来打开Kubernetes的Dashboard:
一些其它有用的命令:
$kubectl cluster-info
$kubectl -s https://192.168.99.100:8443 get componentstatus
$kubectl get componentstatus
$kubectl get nodes
$kubectl config view
$kubectl get pods
$kubectl delete pod my-nginx-m69eo
$kubectl get services
$kubectl get services my-nginx
$kubectl delete service my-nginx
$eval $(minikube docker-env)
$kubectl describe service my-nginxKubernetes使用
在Kubernetes中,主要通过文件来定义API对象,定义文件形式更加清晰,也方便保存和修改,定义格式支持 JSON和YAML。
一个API对象定义了一种期望状态,期望状态在Kubernetes模型中是一个非常重要的概念,当向系统提交
一个期望状态的时候,Kubernetes负责保证当前的状态与期望状态相符。例如,当你创建一个Pod,意味着你
想让其中的容器(s)运行,如果容器没有运行,Kubernetes会持续创建它们力求达到期望状态,这个过程会一
直进行直到这个Pod被删除。
定义Pod:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80该定义文件声明了API对象的基本属性: API版本(apiVersion)、API对象类型(kind)、元数据(metadata)、 规格(spec)。通过定义文件创建Pod:
$kubectl create -f pod-nginx.yaml容器是临时存在的,如果容器被销毁,容器中的数据将会丢失。为了能够持久化数据以及共享容器间的数据,Docker 提出了数据卷(Volume)的概念。数据卷可以绕过默认的联合文件系统(Unionfs),而以正常的文件或目录的 形式存在于宿主机上。Kubernetes对Docker的数据卷进行了扩展,支持对接第三方存储系统。另一方面,Kubernetes 中的数据卷是Pod级别的。Pod中的容器可以访问共同的数据卷,实现容器间的数据共享。下面定义了一个含有 volume的Redis Pod:
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis
volumeMounts:
# name must match the volume name below
- name: redis-persistent-storage
# mount path within the container
mountPath: /data/redis
volumes:
- name: redis-persistent-storage
emptyDir: {}有时候,我们需要两个不同的容器配合起来工作,比如一个web server和一个轮询git库是否有更新的helper job:
apiVersion: v1
kind: Pod
metadata:
name: www
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- name: www-data
mountPath: /srv/www
readOnly: true
- name: git-monitor
image: kubernetes/git-monitor
env:
- name: GIT_REPO
value: http://github.com/some/repo.git
volumeMounts:
- mountPath: /data
name: www-data
volumes:
- name: www-data
emptyDir: {}Kubernetes中的Pod是变化的,特别是收到Replication Controller控制的时候,而当Pod发生变化的时候,Pod的IP 也是变化的。这就导致了一个问题: 在Kubernetes集群中,Pod之间如何互相发现并访问呢?Kubernetes提供了 Service来实现服务发现。
Kubernetes中Service是真实的应用的抽象,用来代理Pod,对外提供固定IP作为访问入口,这样通过访问Service 便能访问到相应的Pod,而对访问者来说只需知道Service的访问地址,而不需要感知Pod的变化:
apiVersion: v1
kind: Service
metadata:
name: redis-master
labels:
name: redis-master
spec:
ports:
# the port that this service should serve on
- port: 6379
targetPort: 6379
selector:
name: redis-master$kubectl create -f redis-master-service.yaml
$kubectl get services
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes 10.0.0.1 <none> 443/TCP 1d
my-nginx 10.0.0.214 <pending> 8080/TCP 4h
redis-master 10.0.0.123 <none> 6379/TCP 2mKubernetes服务发现
微服务架构是一种新流行的架构模式,相比于传统的单块架构模式,微服务架构提倡将应用划分成一组小的服务,每 个服务运行在其独立的进程中,服务之间互相协调、配合,服务与服务之间采用轻量级的通信机制互相沟通。Kubernetes 提供了强大的服务编排能力,微服务化应用的每一个组件都以Service进行抽象,组件和组件之间只需要访问Service 即可相互通信,而无需感知组件的集群变化。
Service用来代理Pod,即可以使用Service的虚拟IP来访问它代理的Pod,但是如果只硬配置Service的虚拟IP到另外 Pod,这不能算是真正的服务发现,Kubernetes提供两种发现Service的方法:
环境变量
当Pod被创建时,Kubernetes会将之前存在的Service的信息通过环境变量的写到Pod中,以Redis Master Service为例, 它的信息会被写到新创建的Pod中:
REDIS_MASTER_SERVICE_HOST=10.0.0.123
REDIS_MASTER_PORT_6379_TCP_PROTO=tcp
REDIS_MASTER_SERVICE_PORT=6379
REDIS_MASTER_PORT=tcp://10.0.0.123:6379
REDIS_MASTER_PORT_6379_TCP=tcp://10.0.0.123:6379
REDIS_MASTER_PORT_6379_TCP_PORT=6379
REDIS_MASTER_PORT_6379_TCP_ADDR=10.0.0.123这种方式要求Pod必须在Service之后启动,之前启动的Pod没有这些环境变量,而采用DNS方式就没有这个限制。
DNS
DNS服务发现方式需要Kubernetes提供Cluster DNS支持,Cluster DNS会监控Kubernetes API,为每一个Service创建DNS 记录,用于域名解析。这样在Pod中就可以通过DNS域名获取Service的访问地址。而对于一个Service,Cluster DNS会创 建两条DNS记录:
[service_name].[namespace_name].[cluster_domain]
[service_name].[namespace_name].svc.[cluster_domain]Minikube安装的环境支持这两种服务发现方式。
弹性伸缩
弹性伸缩是只适应负载变化,以弹性可伸缩的方式提供资源,在虚拟化的支持下提高资源的利用率和用户满意度。 Kubernetes根据负载的高低动态调整Pod的副本数。
$kubectl scale replicationcontroller redis-slave --replicas=3
$kubectl scale rc redis-slave --current-replicas=2 --replicas=1Kubernetes通过Horizontal Pod Autoscalar实现Pod的自动伸缩,Horizontal Pod Autoscalar定时从平台监控 系统中获取Replication Controller关联的Pod的整体资源使用情况。当策略匹配时,通过Replication Controller 来调整Pod的副本数,实现自动伸缩。
apiVersion: extensions/v1beta1
kind: HorizontalPodAutoscaler
metadata:
name: nginx
namespace: default
spec:
scaleRef:
kind: ReplicationController
name: nginx
subresource: scale
minReplicas: 1
maxReplicas: 10
cpuUtilization:
targetPercentage: 50当所有关联Pod的CPU平均使用率超过50%的时候进行扩容,而少于50的时候,进行缩容。另外,可以通过`kubectl autoscale创建Horizontal Pod Autoscaler:
$kubectl atuoscale rc redis-slave --min=1 --max=10 --cpu-percent=50Guestbook例子
上文讲述了搭建Redis Master Service的过程,搭建Redis Slave的过程比较简单,在此不赘述。Guestbook是一个 PHP实现的Web应用,实现了一个将数据写入Redis Master,并从Redis Slave读取的过程。其定义文件如下:
frontend-controller.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: frontend
labels:
name: frontend
spec:
replicas: 3
selector:
name: frontend
template:
metadata:
labels:
name: frontend
spec:
containers:
- name: php-redis
image: gcr.io/google_samples/gb-frontend:v3
env:
- name: GET_HOST_FROM
value: env
ports:
- containerPort: 80这里使用环境变量的方式实现服务发现。使用DNS则将env下的value设置为dns。
frontend-service.yaml
apiVersion: v1
kind: Service
metadata:
name: frontend
labels:
name: frontend
spec:
type: NodePort
ports:
- port: 80
selector:
name: frontendService的虚拟IP是由Kubernetes虚拟出来的内部网络,而外部网络是无法寻址到的,这时候就需要增加一层网络 转发,即外网到内网的转发。Kubernetes提供了NodePort Service、LoadBalancer Service和Ingress来发布Service。 这里采用NodePort的方式来实现,即Kubernetes会在每个Node上设置端口,通过NodePort端口就可以访问到Pod。
$kubectl replace -f frontend-service.yaml --force
service "frontend" deleted
You have exposed your service on an external port on all nodes in your
cluster. If you want to expose this service to the external internet, you may
need to set up firewall rules for the service port(s) (tcp:32278) to serve traffic.
See http://releases.k8s.io/release-1.3/docs/user-guide/services-firewalls.md for more details.
service "frontend" replaced至此我们可以通过任意一个Node的IP:32278来访问Guestbook了,如图:
Kubernetes扩展插件
Kubernetes中提供了许多平台扩展插件(Cluster Add-on),包含在Kubernetes发布包中,可以在Kubernetes上进行 安装部署。
Cluster DNS扩展插件用于支持Kubernetes的服务发现机制,Cluster DNS主要包含如下几项:
- SkyDNS: 提供DNS解析服务
- Etcd: 用于SkyDNS的存储
- Kub2sky: 监听Kubernetes,当有新的Service创建时,生成相应记录到SkyDNS