Flink CDC 2.0 实现原理剖析
Flink CDC Connectors 是 Apache Flink 的一组源端(Source)连接器,通过捕获变更数据(Change Data Capture)从不同数据库中采集数据。项目早期通过集成 Debezium 引擎来采集数据,支持 全量 + 增量 的模式,保证所有数据的一致性。
但因为集成了 Debezium Engine,用户在使用过程中出现了一些痛点:
- 一致性通过加锁保证
- Debezium 在保证数据一致性时,需要对读取的库或表加锁,全局锁可能导致数据库 hang 住,表级锁会锁住表的读
- 不支持水平扩展
- Flink CDC 目前只支持单并发,在全量阶段读取阶段,如果表非常大(亿级别),读取时间在小时级别
- 全量读取阶段不支持 checkpoint
- CDC 读取分为两个阶段,全量读取和增量读取,全量读取阶段不支持 checkpoint,fail 后需要重新读取
Flink CDC 2.0 为了解决如上痛点而设计,借鉴 Netflix DBLog 的无锁算法,并基于 FLIP-27 实现,以达成如下目标:
- 无锁
- 水平扩展
- 支持全量阶段 checkpoint
FLIP-27
在介绍 Flink CDC 2.0 之前,先来了解一下 FLIP-27。FLIP-27 旨在解决 SourceFunction 中存在的几个痛点:
- split 的发现逻辑(work discovery)和实际读取数据的逻辑耦合在
SourceFunction和DataStream接口中,导致 source 实现的复杂性 - 批处理和流处理需要实现不同的 source
- partitions/shards/splits 等概念没有在接口中显示定义,使得很难以独立于源的方式实现事件时间对齐、分区 watermark、动态 split 分配、work stealing 等功能
- checkpoint 锁由 source function 占有会带来一系列问题,导致框架难以优化
- 没有通用框架,这意味着每个 source 都要实现一个复杂的线程模型,增加了新 source 实现及测试的难度
FLIP-27 的 Source API 包含两个组件:
SplitEnumerator负责发现并发现 split,运行在 JobManagerSourceReader负责读取 split 的实际数据,运行在 TaskManager
这两个组件封装了核心功能,使得 Source 接口本身只是一个用于创建 SplitEnumerator 和 SourceReader 的工厂类。下图展示了 SplitEnumerator 和 SourceReader 的拓扑关系。
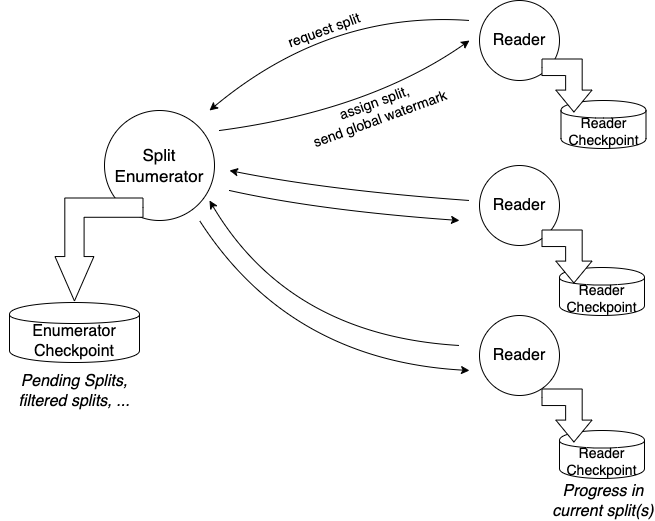
新架构下实现的 source connector 可以做到批流一体,唯一的区别是对批处理 SplitEnumerator 会产出固定数量的 split 集合并且每个 split 都是有限数据集;对于流处理 SplitEnumerator 要么产出无限多的 split 要么 split 自身是无限数据集。
SplitEnumerator 和 SourceReader 需要由用户提供具体的实现类,FLIP-27 在这两个组件之间引入了通用的消息传递机制,通过传递 SourceEvent 接口进行通信,如下图所示:
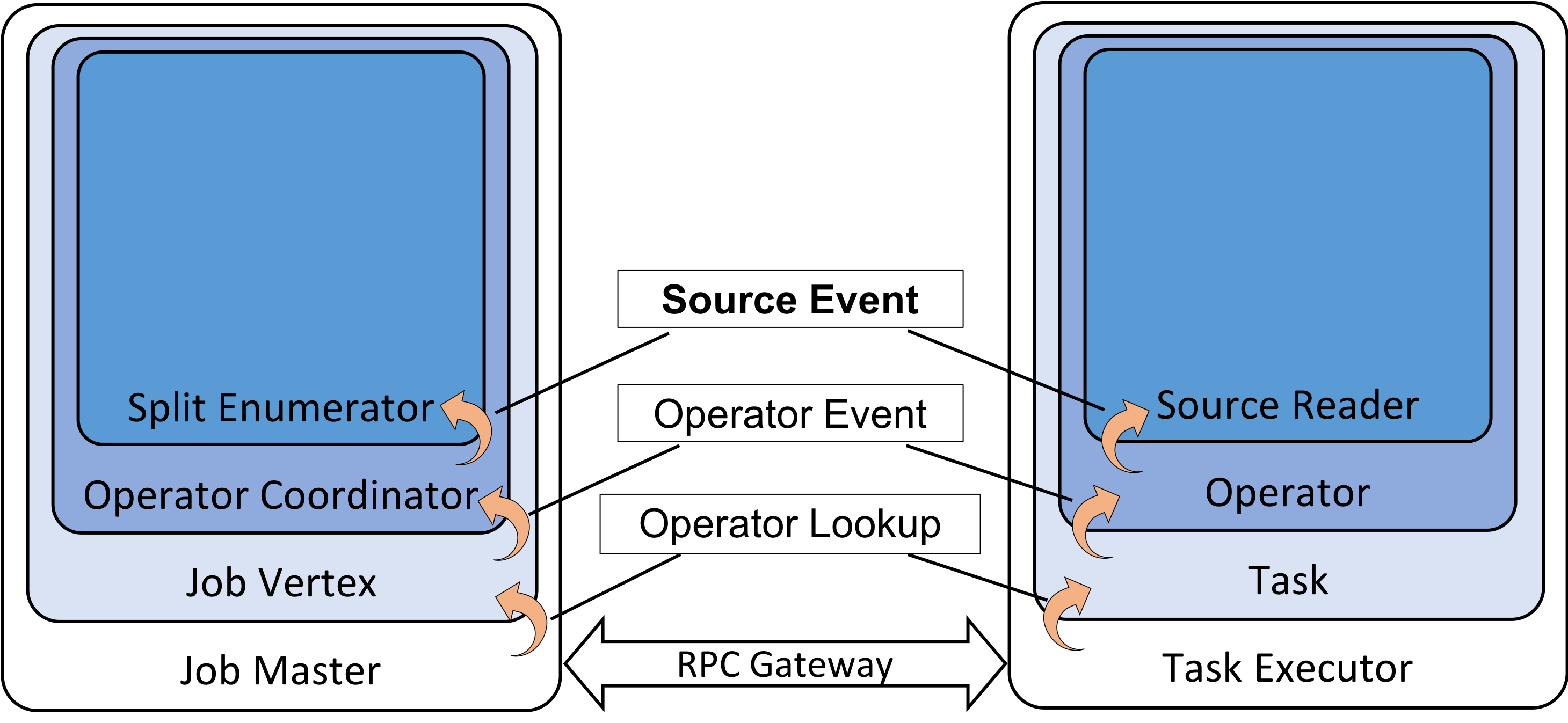
SourceCoordinator 和 SourceOperator 作为上图中 OperatorCoordinator 和 Operator 针对 FLIP-27 的实现,其类结构如下(图中忽略了 Failover 相关结构):

可以看出 SourceCoordinator 封装了 SplitEnumerator,SourceOperator 封装了 SourceReader,在不考虑 Failover 相关结构时,其接口非常简单,Flink 框架调用 SourceCoordinator#start 函数创建 SplitEnumerator 并将其启动,调用 SourceOperator#open 创建、注册并启动 SourceReader,其序列图如下:
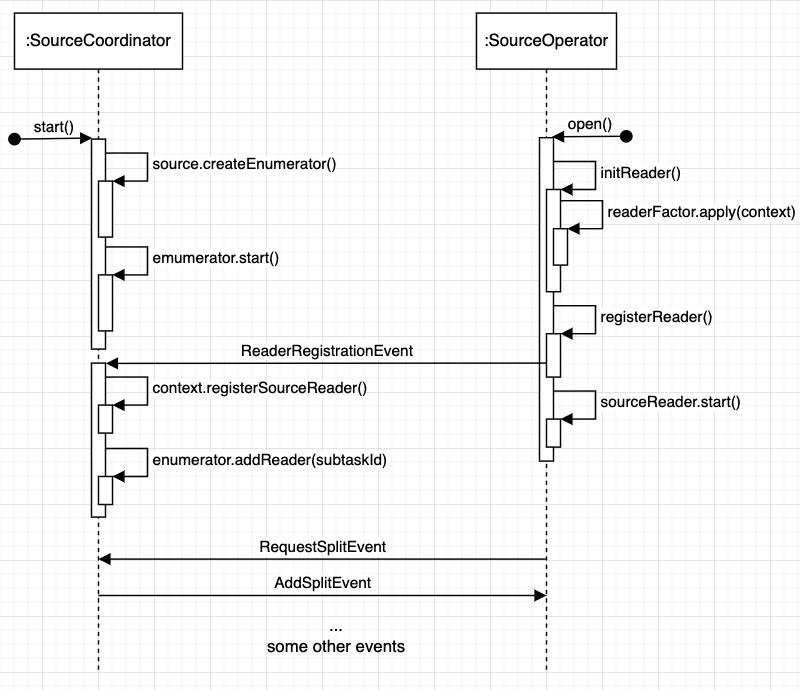
SourceOperator#emitNext 调用 SourceReader#pollNext 接口将读取到的数据传递给下游。
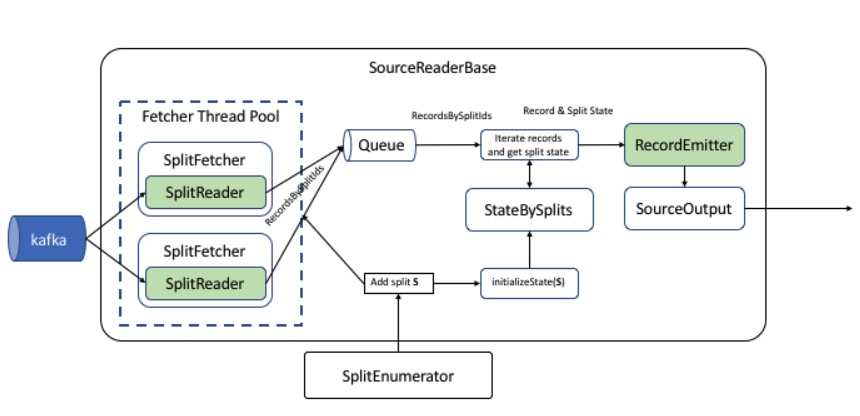
Source 核心接口(the lowest level interface)被设计地非常通用,这使得它非常灵活,但是也增加了复杂 Reader 的实现难度。因此 FLIP-27 中提出了通过构建更高层级的抽象来提供更简单的接口以允许阻塞调用。SourceReaderBase 作为 SourceReader 的一个抽象实现,提供了主线程(mail box main thread)和内部读取线程之间的同步机制,用户只需专注于:
- 从外部系统获取记录(通过实现
SplitReader接口) - 执行记录解析和转换(通过实现
RecordEmitter接口) - 提取时间戳并选择是否处理 watermark
下图展示了 SourceReaderBase 的工作流程:
Flink CDC 2.0 全量增量读取实现原理
FLIP-27 在框架层面提供了多算子并行读取的机制,下面我们来看一下 Flink CDC 2.0 是如何结合 FLIP-27 和 DBLog 无锁算法来实现并发读取全量数据后无缝转换为单线程读取增量数据的。
源端读取的表结构必须具有物理主键,用来将表进行切分,ChunkSplitter 可以根据主键将表均匀切分为 (max - min)/chunkSize 个 split(min/max 指主键的最小值和最大值),或者使用 limit 查询保证一个 split 中有 chunkSize 条数据(最后一个 split 数据记录数 <= chunkSize)。
DBLog 提出的算法叫做 Watermark-based Chunk Selection,通过在源数据库中维护一个单行单列的表作为辅助,在查询每个 chunk(即 split)数据前后分别更新该记录使得在事务日志中生产两个事件 lw(低水位)和 hw(高水位),然后将 select 数据和 [lw, hw] 之间的日志进行处理,获得该 chunk 的 point-in-time 为 hw 的一组数据。与 DBLog 不同,Flink CDC 2.0 没有维护额外的表,而是在 select 数据前后使用 SHOW MASTER STATUS 获取 binlog offset,这种方式避免了侵入源端系统。
快照读取的逻辑:
SHOW MASTER STATUS获取 lw,插入队列- 读取该分片内的记录,插入队列
SHOW MASTER STATUS获取 hw,插入队列- 判断 lw 与 hw 之间是否有增量变更
- 如果没有变更,队列中插入 BINLOG_END 记录
- 否则读取 [lw, hw] 之间的 binlog 并插入队列,最后一条记录为 BINLOG_END
MySqlSnapshotSplitReadTask#doExecute
final BinlogOffset lowWatermark = currentBinlogOffset(jdbcConnection);
LOG.info(
"Snapshot step 1 - Determining low watermark {} for split {}",
lowWatermark,
snapshotSplit);
((SnapshotSplitReader.SnapshotSplitChangeEventSourceContextImpl) (context))
.setLowWatermark(lowWatermark);
signalEventDispatcher.dispatchWatermarkEvent(
snapshotSplit, lowWatermark, SignalEventDispatcher.WatermarkKind.LOW);
LOG.info("Snapshot step 2 - Snapshotting data");
createDataEvents(ctx, snapshotSplit.getTableId());
final BinlogOffset highWatermark = currentBinlogOffset(jdbcConnection);
LOG.info(
"Snapshot step 3 - Determining high watermark {} for split {}",
highWatermark,
snapshotSplit);
signalEventDispatcher.dispatchWatermarkEvent(
snapshotSplit, highWatermark, SignalEventDispatcher.WatermarkKind.HIGH);
((SnapshotSplitReader.SnapshotSplitChangeEventSourceContextImpl) (context))
.setHighWatermark(highWatermark);
上述代码执行后队列中的数据:

然后使用读取 lw 和 hw 之间的 binlog,读取到的数据 append 到同队列,队列中的数据为:

然后对队列里的数据进行修正,获取该分片 point-in-time 为 hw 的数据。
RecordUtils#normalizedSplitRecords
// 根据高低水位将 snapshot records 和 binlog records 分开
SourceRecord lowWatermark = sourceRecords.get(0);
SourceRecord highWatermark = null;
int i = 1;
for (; i < sourceRecords.size(); i++) {
SourceRecord sourceRecord = sourceRecords.get(i);
if (!isHighWatermarkEvent(sourceRecord)) {
snapshotRecords.put((Struct) sourceRecord.key(), sourceRecord);
} else {
highWatermark = sourceRecord;
i++;
break;
}
}
// binlog records 中包含了非本分片的日志,需要将属于本分片的日志过滤出来
if (i < sourceRecords.size() - 1) {
List<SourceRecord> allBinlogRecords =
sourceRecords.subList(i, sourceRecords.size() - 1);
for (SourceRecord binlog : allBinlogRecords) {
if (isDataChangeRecord(binlog)) {
Object[] key =
getSplitKey(snapshotSplit.getSplitKeyType(), binlog, nameAdjuster);
if (splitKeyRangeContains(
key, snapshotSplit.getSplitStart(), snapshotSplit.getSplitEnd())) {
binlogRecords.add(binlog);
}
}
}
}
// 将 snapshot records 和 binlog records 进行 upsert 逻辑得到 point-in-time 为 hw 的数据
normalizedRecords =
upsertBinlog(
snapshotSplit,
lowWatermark,
highWatermark,
snapshotRecords,
binlogRecords);
upsertBinlog 逻辑:
- 将 lw 加入到 normalizedBinlogRecords
- 遍历 binlogRecords 中的记录
- 对于删除记录,将其从 snapshotRecords 删除
- 对于更新记录,将记录中的 After 作为 READ 记录 map.put 到 snapshotRecords
- 对于创建记录,使用 map.put 到 snapshotRecords 中
- 将 snapshotRecords.values 加入到 normalizedBinlogRecords
- 将 hw 加入到 normalizedBinlogRecords
- 返回 normalizedBinlogRecords
private static List<SourceRecord> upsertBinlog(
MySqlSplit split,
SourceRecord lowWatermarkEvent,
SourceRecord highWatermarkEvent,
Map<Struct, SourceRecord> snapshotRecords,
List<SourceRecord> binlogRecords) {
final List<SourceRecord> normalizedBinlogRecords = new ArrayList<>();
normalizedBinlogRecords.add(lowWatermarkEvent);
// upsert binlog events to snapshot events of split
if (!binlogRecords.isEmpty()) {
for (SourceRecord binlog : binlogRecords) {
Struct key = (Struct) binlog.key();
Struct value = (Struct) binlog.value();
if (value != null) {
Envelope.Operation operation =
Envelope.Operation.forCode(
value.getString(Envelope.FieldName.OPERATION));
switch (operation) {
case UPDATE:
Envelope envelope = Envelope.fromSchema(binlog.valueSchema());
Struct source = value.getStruct(Envelope.FieldName.SOURCE);
Struct updateAfter = value.getStruct(Envelope.FieldName.AFTER);
Instant ts =
Instant.ofEpochMilli(
(Long) source.get(Envelope.FieldName.TIMESTAMP));
SourceRecord record =
new SourceRecord(
binlog.sourcePartition(),
binlog.sourceOffset(),
binlog.topic(),
binlog.kafkaPartition(),
binlog.keySchema(),
binlog.key(),
binlog.valueSchema(),
envelope.read(updateAfter, source, ts));
snapshotRecords.put(key, record);
break;
case DELETE:
snapshotRecords.remove(key);
break;
case CREATE:
snapshotRecords.put(key, binlog);
break;
case READ:
throw new IllegalStateException(
String.format(
"Binlog record shouldn't use READ operation, the the record is %s.",
binlog));
}
}
}
}
normalizedBinlogRecords.addAll(snapshotRecords.values());
normalizedBinlogRecords.add(highWatermarkEvent);
return normalizedBinlogRecords;
}
上述过程在多个 SourceReader 上并发执行,互不影响。假设一个任务同步的三张表 t1/t2/t3 被切分为 6 个分片,由于并发执行,其高低水位在 binlog 上的位置的一种可能如下图所示:
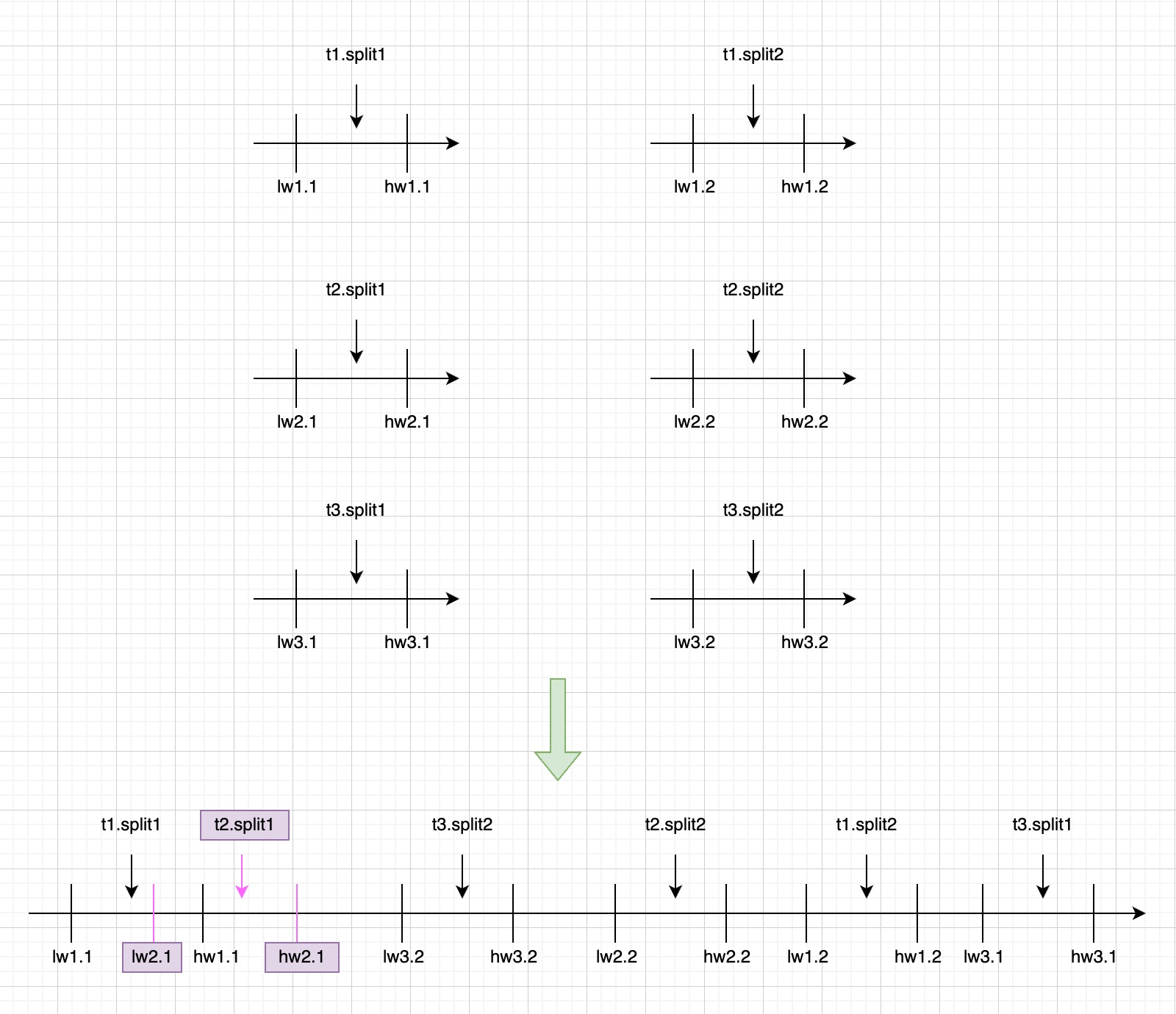
可以看出,t1.split1 和 t2.split1 读取的 binlog 范围有交叉(都读取了 [lw2.1, hw1.1] 之间的 binlog),t3.split2 可以早于 t3.split1 执行。这些交叉或者乱序并不影响正确性,因为全量阶段 MySqlSourceReader 会将每个 split 的 hw 通过 FinishedSnapshotSplitsReportEvent 消息汇报给 MySqlSourceEnumerator,在增量阶段通过这些 hw 信息来保证任意一条 binlog 记录不被重复处理。
MySqlSourceReader#reportFinishedSnapshotSplitsIfNeed
private void reportFinishedSnapshotSplitsIfNeed() {
if (!finishedUnackedSplits.isEmpty()) {
final Map<String, BinlogOffset> finishedOffsets = new HashMap<>();
for (MySqlSnapshotSplit split : finishedUnackedSplits.values()) {
finishedOffsets.put(split.splitId(), split.getHighWatermark());
}
FinishedSnapshotSplitsReportEvent reportEvent =
new FinishedSnapshotSplitsReportEvent(finishedOffsets);
context.sendSourceEventToCoordinator(reportEvent);
LOG.debug(
"The subtask {} reports offsets of finished snapshot splits {}.",
subtaskId,
finishedOffsets);
}
}
当 MySqlSourceEnumerator 将所有 split 的 hw 收齐之后,会创建一个 binlog split,该分片包含了需要读取 binlog 的起始位置(所有分片 hw 的最小值)和所有分片的 hw 信息。
MySqlHybridSplitAssigner#createBinlogSplit
private MySqlBinlogSplit createBinlogSplit() {
final List<MySqlSnapshotSplit> assignedSnapshotSplit =
snapshotSplitAssigner.getAssignedSplits().values().stream()
.sorted(Comparator.comparing(MySqlSplit::splitId))
.collect(Collectors.toList());
Map<String, BinlogOffset> splitFinishedOffsets =
snapshotSplitAssigner.getSplitFinishedOffsets();
final List<FinishedSnapshotSplitInfo> finishedSnapshotSplitInfos = new ArrayList<>();
BinlogOffset minBinlogOffset = null;
for (MySqlSnapshotSplit split : assignedSnapshotSplit) {
// find the min binlog offset
BinlogOffset binlogOffset = splitFinishedOffsets.get(split.splitId());
if (minBinlogOffset == null || binlogOffset.isBefore(minBinlogOffset)) {
minBinlogOffset = binlogOffset;
}
finishedSnapshotSplitInfos.add(
new FinishedSnapshotSplitInfo(
split.getTableId(),
split.splitId(),
split.getSplitStart(),
split.getSplitEnd(),
binlogOffset));
}
// the finishedSnapshotSplitInfos is too large for transmission, divide it to groups and
// then transfer them
boolean divideMetaToGroups = finishedSnapshotSplitInfos.size() > splitMetaGroupSize;
return new MySqlBinlogSplit(
BINLOG_SPLIT_ID,
minBinlogOffset == null ? BinlogOffset.INITIAL_OFFSET : minBinlogOffset,
BinlogOffset.NO_STOPPING_OFFSET,
divideMetaToGroups ? new ArrayList<>() : finishedSnapshotSplitInfos,
new HashMap<>(),
finishedSnapshotSplitInfos.size());
}
当 MySqlSourceEnumerator 把该 binlog 分片 assign 给一个 MySqlSourceReader 的时候,任务从全量阶段转为增量阶段。MySqlSourceReader 在读取 binlog 数据后,通过 shouldEmit 来判断该记录是否应该发送给下游。
private boolean shouldEmit(SourceRecord sourceRecord) {
if (isDataChangeRecord(sourceRecord)) {
TableId tableId = getTableId(sourceRecord);
BinlogOffset position = getBinlogPosition(sourceRecord);
if (hasEnterPureBinlogPhase(tableId, position)) {
return true;
}
// only the table who captured snapshot splits need to filter
if (finishedSplitsInfo.containsKey(tableId)) {
RowType splitKeyType =
ChunkUtils.getSplitType(
statefulTaskContext.getDatabaseSchema().tableFor(tableId));
Object[] key =
getSplitKey(
splitKeyType,
sourceRecord,
statefulTaskContext.getSchemaNameAdjuster());
for (FinishedSnapshotSplitInfo splitInfo : finishedSplitsInfo.get(tableId)) {
if (RecordUtils.splitKeyRangeContains(
key, splitInfo.getSplitStart(), splitInfo.getSplitEnd())
&& position.isAfter(splitInfo.getHighWatermark())) {
return true;
}
}
}
// not in the monitored splits scope, do not emit
return false;
}
// always send the schema change event and signal event
// we need record them to state of Flink
return true;
}
当一个 binlog 记录属于一个分片的主键范围内时,如果该记录在这个分片的 hw 之后,则该记录应该发送给下游。BinlogSplitReader 通过配置 maxSplitHighWatermarkMap 来判断一条记录是否已经处其所在表的最大 hw,即该表是否已经进入 Pure Binlog Phase,对于这样的 binlog 记录,不需进行比较,直接发送给下游。
全量读取阶段支持 checkpoint
通过上一节的介绍,我们了解了 Flink CDC 2.0 借鉴 DBLog 的算法实现了无锁读取,借助 FLIP-27 框架优雅地实现了全量阶段的并发读取。对于 checkpoint,通过实现 FLIP-27 定义的接口,能够保证重启之后恢复到之前的状态,已完成的 split 不会重新读取。
MySqlSourceEnumerator 端的状态管理在 link-connector-mysql-cdc/src/main/java/com/ververica/cdc/connectors/mysql/source/assigners/state/ 目录下实现,MySqlSourceReader 端的状态管理在 flink-connector-mysql-cdc/src/main/java/com/ververica/cdc/connectors/mysql/source/split/ 目录下实现,由于这块的逻辑相对更加复杂,本文不作进一步介绍。
存在的问题
细心的读者可能会发现,全量阶段转为增量阶段后,如果较早读取的 binlog 在源端被 purge,增量阶段会因为读取不到对应的 binlog 位置而报错。该问题是因为 Flink CDC 没有持久化存储来确保任务开始之后的 binlog 都被保存。提高并行度加速全量阶段的吞吐一定程度上能缓解该问题。
社区动态
截至版本 Release-2.1.1,只有 flink-connector-mysql-cdc 支持上述的 CDC 2.0 特性,在 Release-2.2 Roadmap 中,一个关键特性是将 2.0 的框架抽取出来,以支持其它数据库 connector 使用 2.0 特性,详见 PR。