MySQL 主从复制实践
MySQL 主从复制是一个通过自动将主库数据复制到从数据库的过程,使得用户可以轻松维护数据的多个副本。多副本不仅可以增强数据的安全性,通过实现读写分离还能提升数据库的负载能力。本文试图详尽地描述主从复制的过程。
本文使用的主机如下:
| Name | ADDRESS | OS Distribution | MySQL |
|---|---|---|---|
| master | 10.0.63.202 | CentOS7 | Ver 14.14 Distrib 5.6.38 |
| slave | 10.0.63.203 | CentOS7 | Ver 14.14 Distrib 5.6.38 |
安装MySQL
这里简单提一下CentOS安装MySQL的过程,原因有二:
- CentOS7 发行版中的源默认为MariaDB
- MySQL 官方的安装文档有些晦涩,这部分内容方便笔者后续查看
如果读者对MySQL的安装非常了解,请跳过该部分内容 :)
## 从官网 https://dev.mysql.com/downloads/repo/yum/ 下载相应系统对应MySQL版本的Yum源
## 这里可能让人疑惑的是没有显示标明CentOS应该下载哪个,Red Hat Enterprise Linux 的即可
## 另外一个可能疑惑的地方是只有57版本的repo packages, 其实它包含了该发行版可用的所有
## MySQL版本,只不过默认启用的版本为5.7,可使用`yum repolist all | grep mysql` 查看
[root@master ~]# wget https://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm
## 使用如下命令安装源
[root@master ~]# sudo rpm -Uvh mysql57-community-release-el7-11.noarch.rpm
## 或
[root@master ~]# sudo yum localinstall mysql57-community-release-el7-11.noarch.rpm
## 弃用5.7版本,启用5.6版本
[root@master ~]# sudo yum-config-manager --disable mysql57-community
[root@master ~]# sudo yum-config-manager --enable mysql56-community
## 查看启用的MySQL源
[root@master ~]# yum repolist enabled | grep "mysql.*-community.*"
!mysql-connectors-community/x86_64 MySQL Connectors Community 42
!mysql-tools-community/x86_64 MySQL Tools Community 55
!mysql56-community/x86_64 MySQL 5.6 Community Server 361
## 设置好源之后使用如下命令来安装MySQL
[root@master ~]# sudo yum install mysql-community-server
## 查看版本
[root@master ~]# mysqld -V
mysqld Ver 5.6.38 for Linux on x86_64 (MySQL Community Server (GPL))
## 启动并设置开机启动
[root@master ~]# systemctl start mysqld.service
[root@master ~]# sudo systemctl enable mysqld.service
## Securing the MySQL Installation
## 在安装5.6版本时需要进行该操作,根据提示设置root密码,删除匿名用户等
## 5.7版本需要不同的操作,详见https://dev.mysql.com/doc/mysql-yum-repo-quick-guide/en/
[root@master ~]# mysql_secure_installation
以上是 MySQL 5.6 的安装过程,安装完成后往往还需要修改配置以获取较优的性能:
数据库配置
/etc/my.cnf
## [client] option group is read by all client programs provided in MySQL distributions (but not by mysqld)
[client]
default-character-set = utf8
## [mysql] option group apply specifically to mysql client program
[mysql]
# 更改默认字符集以免引发乱码
default-character-set = utf8
## [mysqld] option group apply specifically to mysqld server program
[mysqld]
# Typical values are 5-6GB (8GB RAM), 20-25GB (32GB RAM), 100-120GB (128GB RAM)
innodb_buffer_pool_size = 6G
# 客户端最大并发连接数量,default: 151
max_connections = 1000
# 在检查客户端连接时,不要解析主机名,只使用IP地址
# 该选项要求grant表中的所有主机值必须是IP地址或localhost
skip-name-resolve
# 在Windows或OS X系统中,文件系统不区分大小写
# 设置为1,表文件全部以小写命名
lower_case_table_names = 1
# Server允许发送和接收的最大消息包大小,default: 4MB
# 使用大的BLOB列或长字符串,需要增加该值,它应该和你要使用的最大BLOB一样大
max_allowed_packet = 20M
# 设置字符集为 utf8
character-set-server = utf8
# 每个客户端连接数据库之后首先执行的一条命令,也是为了查询到乱码
init_connect = 'SET NAMES utf8'
# 可以使用 `show collation;` 来查看每个字符集可用的排序规则
# `show variables like "%character%";show variables like "%collation%";` 来查看当前设置的字符集及排序规则
# ci => case insensitive
collation-server = utf8_unicode_ci
## omit other default options and option group
...
注:所有可配置的选项都可以通过相应的命令查看,如 mysqld --verbose --help、mysql --verbose --help。或查看手册 Server Option and Variable Reference、mysql Options。
Master/Slave Setup
回到正题。在讨论设置主从复制的细节之前,我们先简单了解一下 MySQL 是如何复制数据的,直观上,复制包括三个过程:
- 主节点将数据的变动记录到 binary log (这些记录被称作 binary log events)
- 从节点通过网络将主节点的 binary log events 复制到从节点的 relay log
- 从节点重放(replay) relay log 中的事件,将这些变动应用到从节点的数据上
下图显示了这一过程:
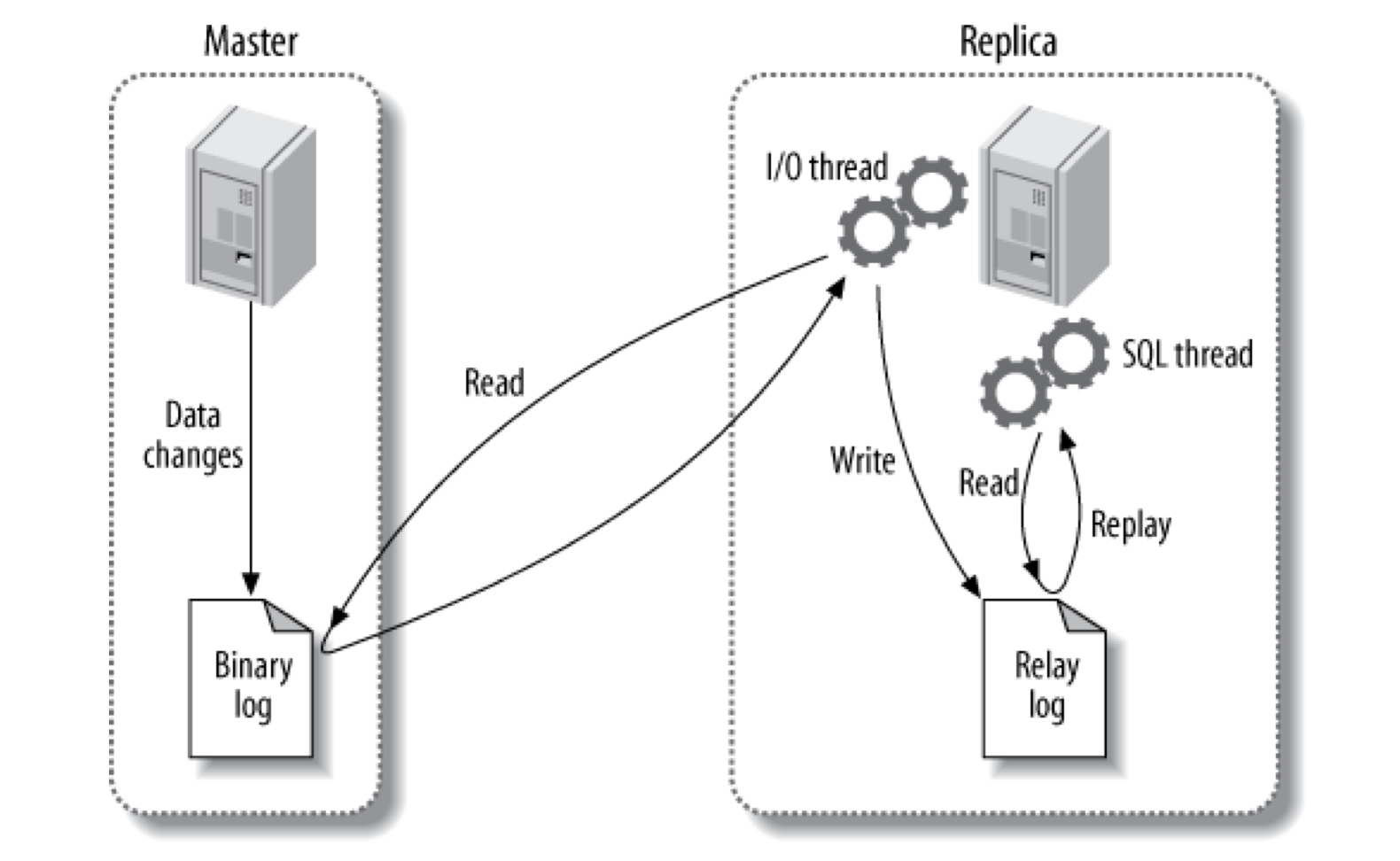
更细节的部分可翻阅《High Performance MySQL, 3rd Edition》第10章进行查看。
配置主节点
master /etc/my.cnf
server-id = 1
log-bin = mysql-bin
# 当InnoDB存储引擎需要处理事务,为了尽可能满足持久性和一致性,应该设置如下两项
innodb_flush_log_at_trx_commit = 1
sync_binlog = 1
需要在主节点上设置一个可供从节点连接的账号,并赋予相应的权限:
mysql> GRANT REPLICATION SLAVE ON *.* TO slave@'10.0.63.%' IDENTIFIED BY 'p4ssword';
然后把主库的数据使用 mysqldump 保存到一个文件中:
## -A => --all-databases
## --skip-lock-tables => --opt 是 --add-drop-table --add-locks --create-options
## --disable-keys --extended-insert --lock-tables --quick
## --set-charset 选项的组合,默认是生效的,当使用 InnoDB
## 时,--single-transation 是一个比 --lock-tables 更好的选
## 项,因此使用 --skip-lock-tables 来禁掉 --lock-tables
## --single-transaction => 通过将导出操作封装在一个事务内来使得导出的数据是一个
## 一致性快照, 依赖 InnoDB 的 MVCC 机制。
## --flush-logs => 导出之前先刷新服务器日志文件
## --hex-blog => 使用十六进制表示法导出二进制(如:'abc' 导出为 0x616263)
## --master-data=2 => 将 binlog 的坐标作为注释记录到导出文件中,用于后续操作
## 以上参数详见 https://dev.mysql.com/doc/refman/5.6/en/mysqldump.html
[root@master ~]# mysqldump -uroot -p --skip-lock-tables --single-transaction --flush-logs
--hex-blob --master-data=2 -A > all-databases.sql
上面的 –single-transaction 和 –master-data=2 选项组合在导出数据前做了如下几件事:
- FLUSH TABLES WITH READ LOCK;
- SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
- START TRANSACTION;
- SHOW MASTER STATUS;
- UNLOCK TABLES;
什么意思呢?就是说这条命令在运行的时候既保证保证了导出的数据是 binary log 坐标(MASTER_LOG_FILE, MASTER_LOG_POS)位置的数据库快照,又不影响后续写命令的执行。
由于上述命令将 binlog 坐标作为注释记录在了 all-databases.sql 文件中,因此可以使用如下命令获取:
[root@master ~]# head all-databases.sql -n80 | grep "MASTER_LOG_POS"
-- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000002', MASTER_LOG_POS=120;
然后将 all-databases.sql 传输到从节点上(如果数据文件较大,可用 gzip 压缩后再传输)。
需要注意的一点,FLUSH TABLES WITH READ LOCK; 命令在获取全局读锁之前,必须等待所有的查询结束,如果有长时间的查询操作,将会使得该操作的过程非常漫长,并导致整个数据库处于只读状态甚至连读操作都会阻塞(见参考8~13)。因此,mysqldump 操作应该选择在数据库负载最小的时刻进行。
配置从节点
slave /etc/my.cnf
server-id=2
# 在从节点开启 log_bin 和 log-slave-update 可用于配置级联复制架构
log_bin = mysql-bin
log-slave-update = 1
relay-log = mysql-relay-bin
# the server permits no client updates except from users who have the SUPER privilege
read-only = 1
重新启动 Slave Server 并将 all-databases.sql 的语句在 Slave Server 执行。
[root@slave ~]# systemctl restart mysqld.service
[root@slave ~]# mysql -uroot -p < all-databases.sql
执行完上述命令之后,从节点的数据库就跟 binlog 坐标点的数据一模一样了。接下来就是进入从节点 MySQL 的控制台,告诉它应该从主节点的什么位置进行接下来的同步了:
mysql> CHANGE MASTER TO MASTER_HOST='10.0.63.202',MASTER_USER='slave',MASTER_PASSWORD='p4ssword',MASTER_LOG_FILE='mysql-bin.000002',MASTER_LOG_POS=120;
Query OK, 0 rows affected, 2 warnings (0.01 sec)
mysql> START SLAVE;
Query OK, 0 rows affected (0.03 sec)
查看 Slave 状态命令:
mysql> SHOW SLAVE STATUS \G
以上为 MySQL 主从复制的过程,其中比较关键的是如何获取 mysqldump 运行时的数据库快照和 binlog 的坐标,即充分理解几个参数的含义。
在写本文之前,笔者对主从复制存有一些疑问,经过两天的调研整理,基本能把之前的疑问做一简单回答,如下:
1. 是否需要选择需要备份的库?
对于现在我接触到的应用,基本上是多个微服务各自对应一个数据库(database),但却同时存在于一个 MySQL Server 上。备份的时候使用 –all-databases 选项可将所有数据库(–all-databases 选项不会备份 performance_schema 和 information_schema)导出到文件,并后续同步到 slave 节点。在配置文件中没有配置 binlog-do-db,会将所有数据库的变动写入 binary log,包括创建database的命令。
如果是一个微服务对应一个 MySQL Server 的场景,既然只有一个库了,备份整个库也无所谓啊:)
2. 如何处理存储过程、函数及触发器?
这个问题之前一直困扰着我,通过调研,发现它们存储在 mysql database 中,mysqldump –all-databases 会将 mysql 数据库导出,使得从节点与主节点拥有一样的 mysql 数据库,而任何新创建的存储过程、函数及触发器都会写到 binary log 中,进而同步到从节点的 mysql 数据库。因此,只需要操作主节点的 MySQL Server,而不需对从节点进行任何操作。
3. 如果需要变动表结构需要如何处理?
如果没有配置 binlog-do-db,那么任何数据库的改动都会写入 binary log,因此,也不用关心从节点。
4. 如果新增数据库需要如何处理?
同问题3。
5. 如果需要将一主一丛扩展为一主二从应该如何操作?
选则在主节点负载最小的时刻再进行一次上面的操作即可。
结语
本文仅介绍了一种 MySQL 的主从复制过程,还有很多其它方法(如利用文件系统的snapshot或Percona XtraBackup 工具)可能有更好的性能,在今后的实践中会进行尝试。
另外,在查阅资料的过程中在 MySQL 官网上看到了 InnoDB Cluster 和 MySQL NDB Cluster 相关的内容。前者通过将一组 MySQL Server 配置为一个集群,在默认额单主节点模式下,集群具有一个读写主节点和多个只读副节点,客户端程序通过连接 MySQL Router,Router 会选择一个合适的 Server 来提供服务;后者通过 NDB 存储引擎提供存储能力,SQL 层(mysqld)负责存储层之上的所有事情,如连接管理,query 优化及响应,Cache 管理等等。这些笔者还没有进行深入了解,这里列出作为后续调研的方向。
– 20180119 更新 –
当应用连接到主库进行测试的时候,出现了如下错误:
SQL Error: 1418, SQLState: HY000
This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary
logging is enabled (you *might* want to use the less safe log_bin_trust_function_creators variable)
原因是因为 SQL 语句中含有存储程序(stored precedures and functions/triggers/events),如:
SELECT distinct a.permission_value FROM auth_permission a INNER JOIN auth_role_permission b
ON a.id=b.permission_id INNER JOIN auth_user_role c ON b.role_id=c.role_id
WHERE a.deleted=0 and c.user_id=? AND FIND_IN_SET(a.id, getPermissionChildList(?))
如果该语句被路由到 Slave 节点且 getPermissionChildList 含有更改数据的操作,会造成主从库不一致,存在安全隐患,所以 MySQL 默认禁止这种操作。如果明确知道存储程序不会造成主从库不一致,则可以以通过以下两种方式放宽这一限制:
- 在 MySQL 控制台执行
SET GLOBAL log_bin_trust_function_creators = 1; - 在配置文件中添加
log_bin_trust_function_creators = 1;并重新启动