3台机器部署Kubernetes集群
etcd是Kubernetes依赖的一个非常重要的组件,ectd ABC一文介绍了在三台机器上搭建etcd cluster的过程,本文介绍在这三台机器上搭建Kubernetes cluster。
三台机器的网络配置如下:
| HOSTNAME | ADDRESS |
|---|---|
| anakin | 10.0.63.202/172.0.63.202 |
| boba | 10.0.63.203/172.0.63.203 |
| c3po | 10.0.63.204/172.0.63.204 |
下载Kubernetes Release包(v1.3.5)
[root@anakin ~]# wget https://github.com/kubernetes/kubernetes/releases/download/v1.3.5/kubernetes.tar.gz如果网络性能不好,下载过程可能会中断,则建议使用迅雷将包下载后拷贝到集群中的每一台机器,解压缩并拷贝到系统可执行目录/usr/bin下:
[root@anakin ~]# tar -xmvf Kubernetes.tar.gv
[root@anakin ~]# cd kubernetes/server
[root@anakin ~]# tar -xmvf kubernetes-server-linux-amd64.tar.gz
[root@anakin ~]# cd kubernetes/server/bin/
[root@anakin ~]# find ./ -perm 755 | xargs -i cp {} /usr/binKubernetes Master
第一台机器anakin作为Kubernetes Master,其上运行如下组件:
- Kubernetes API Server
- Kubernetes Controller Manager
- Kubernetes Scheduler
- Kubernetes Proxy
Kubernetes API Server
由于环境中的etcd集群已经搭建好,指定–etcd-servers为本机IP:2379即可。–insecure-bind-address设置为0.0.0.0意味着在所有网卡接口都提供服务。
[root@anakin ~]# nohup kube-apiserver --logtostderr=true --v=0 \
--admission-control=AlwaysAdmit --allow-privileged=true \
--etcd-servers=http://localhost:2379 --insecure-bind-address=0.0.0.0 \
--insecure-port=8080 --service-cluster-ip-range=10.254.0.0/16 \
>> /var/log/kube-apiserver.log 2>&1 &--allow-privileged=true启动参数用于DaemonSet类型的组件。
Kubernetes Controller Manager
[root@anakin ~]# nohup kube-controller-manager --logtostderr=true --v=0 \
--service-account-private-key-file=/var/run/kubernetes/apiserver.key
--master=http://10.0.63.202:8080 >> /var/log/kube-controller-manager.log 2>&1 &上述的apiserver.key由apiserver启动时创建的,除key之外,还有一个apiserver.crt证书文件。
Kubernetes Schedule
[root@anakin ~]# nohup kube-scheduler --logtostderr=true --v=0 \
--master=http://10.0.63.202:8080 >> /var/log/kube-scheduler.log 2>&1 &Kubernetes Proxy
[root@anakin ~]# nohup kube-proxy --logtostderr=true --v=0 \
--master=http://10.0.63.202:8080 >> /var/log/kube-proxy.log 2>&1 &Node需要同Master的8080端口进行socket通信,使用如下命令将anakin的8080端口打开:
[root@anakin ~]# firewall-cmd --zone=dmz --add-port=8080/tcp --permanent
[root@anakin ~]# firewall-cmd --reload使用firewall-cmd --zone=dmz --list-ports命令查看打开的端口。
Kubernetes Node
boba和c3po作为Kubernetes的Node,其上需要运行:
- Docker
- Kubelet
- Kubernetes Proxy
根据Docker官方安装文档安装Docker。
Kubelet
[root@boba ~]# nohup kubelet --logtostderr=true --v=0 --address=0.0.0.0 \
--api-servers=http://10.0.63.202:8080 --register-node=true \
--allow-privileged=true --cluster-dns=10.254.10.2 --cluster-domain=cluster.local \
>> /var/log/kubelet.log 2>&1 &--cluster-dns和--cluster-domain需要在创建DNS扩展插件之后添加上重启。
Kubernetes Proxy
[root@boba ~]# nohup kube-proxy --logtostderr=true --v=0 \
--master=http://10.0.63.202:8080 >> /var/log/kube-proxy.log 2>&1 &在Master节点上也可以运行上述命令,让Master节点也作为运行Pod的计算资源。但这是否是一种好的方式还有待调研。
查询Kubernetes的健康状态
[root@anakin ~]# kubectl -s http://10.0.63.202:8080 get componentstatus
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health": "true"}
[root@anakin ~]# kubectl -s http://10.0.63.202:8080 get node
NAME STATUS AGE
boba Ready 1h
c3po Ready 1hKubernetes覆盖网络
Kubernetes的网络模型要求每一个Pod都拥有一个扁平化共享网络命名空间的IP,称为PodIP,Pod能够通过PodIP跨网络与其他物理机和Pod进行通信。要实现Kubernetes的网络模型,需要在Kubernetes集群中创建一个覆盖网络(Overlay Network),联通各个节点,如Flannel和Open vSwitch。本文对Flannel进行部署及验证。
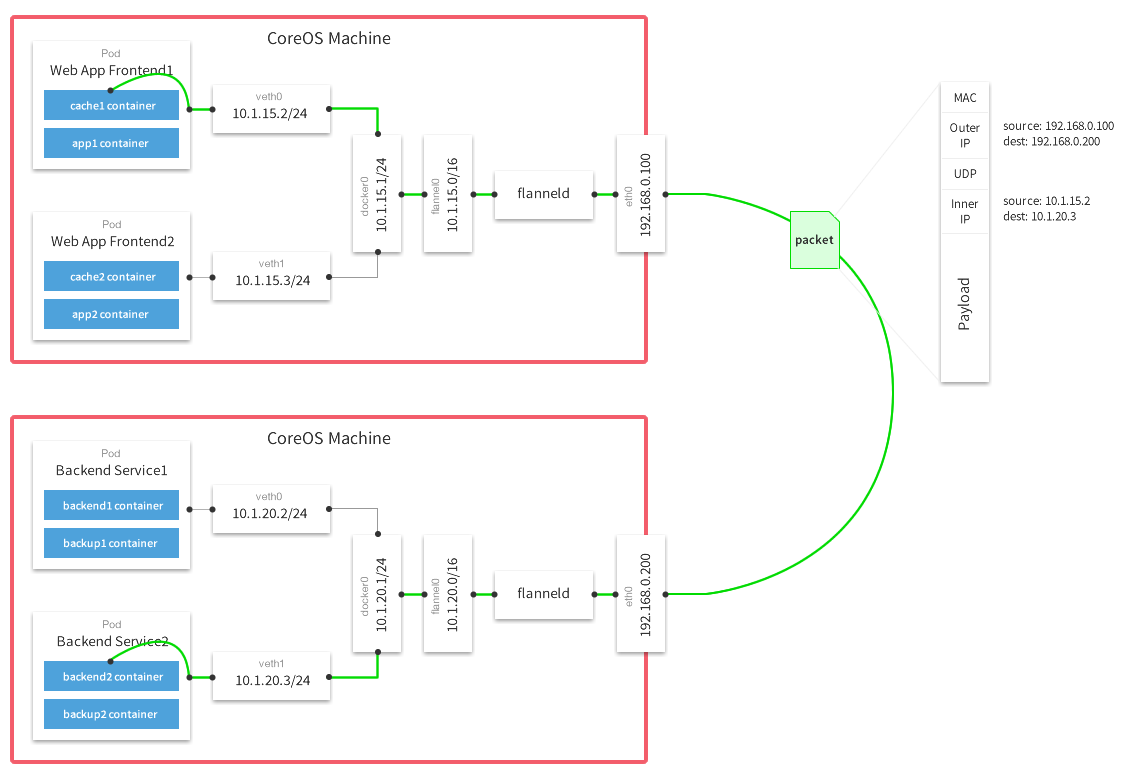
flanneld作为一个中间层,对不同Host上的虚拟地址网段进行监控管理转发,图中绿色的线是包转发的路径。Flannel支持不同的模式,如udp、vxlan、host-gw、aws-vpc,本文配置为udp模式。
Flannel同样需要etcd作为共享配置的数据仓库,由于三台机器上都运行etcd监听服务,因此Flannel的配置变得非常简单:
在任意一台机器上运行:
[root@anakin ~]# etcdctl set atomic.io/network/config '{"Network":"10.0.0.0/16"}'在各机器上分别进行如下操作:
安装并运行flanneld:
[root@anakin ~]# yum install -y flanneld
[root@anakin ~]# systemctl start flanneld.service
[root@anakin ~]# cat /run/flannel/subnet.env
FLANNEL_NETWORK=10.0.0.0/16
FLANNEL_SUBNET=10.0.7.1/24
FLANNEL_MTU=1472
FLANNEL_IPMASQ=false编辑/lib/systemd/system/docker.service,编辑ExecStart开头的行:
ExecStart=/usr/bin/dockerd --bip=10.0.7.1/24 --mtu=1472
重启docker:
[root@anakin ~]# systemctl daemon-reload
[root@anakin ~]# systemctl restart docker.service另外,由于重启docker,造成了etcd容器的stop,因此需要将停止的etcd容器重新启动,由于集群中有三台etcd节点,因此这个过程不会影响etcd的健康状态。
在三台机器上分别进行如上操作之后,flannel的网络模型如下图所示(用ip a | grep flannel查看flanneld网络):
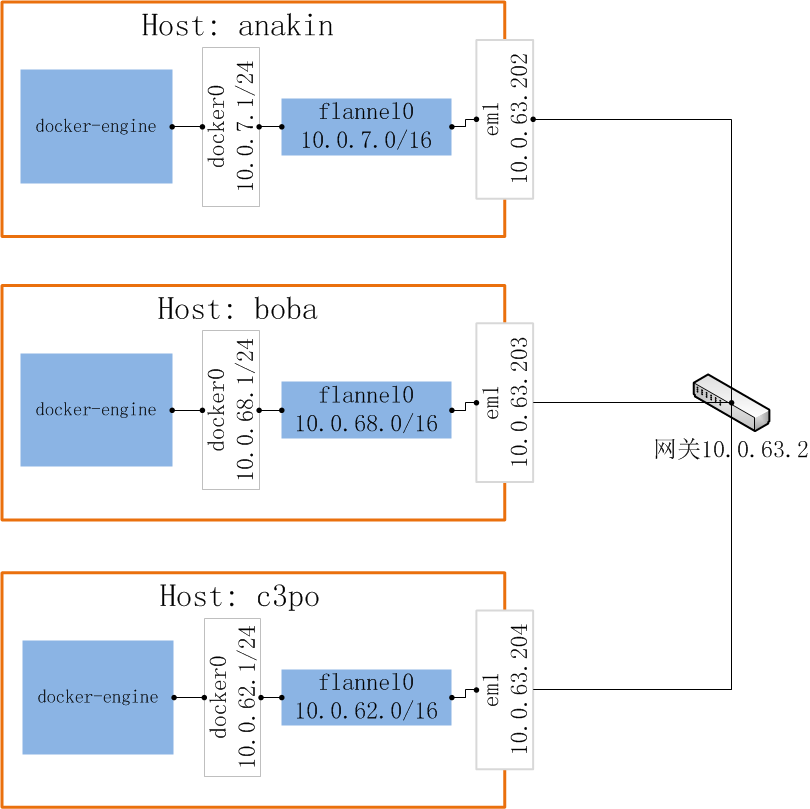
在各机器上可以查看docker的子网详情:
[root@anakin ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
b9d64daa5086 bridge bridge local
ea071bdf6e22 host host local
e3d962a74d98 none null local
[root@anakin ~]# docker network inspect b9d64daa5086
[
{
"Name": "bridge",
"Id": "b9d64daa50867bb288161c0d419d5ad5ae6f4b0a1f6e579c92421dc269e990d0",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": null,
"Config": [
{
"Subnet": "10.0.7.1/24",
"Gateway": "10.0.7.1"
}
]
},
"Internal": false,
"Containers": {
"47f33a75f927192fe5804e21e45917298ac977f7615cd4010179e8d4fd8d6077": {
"Name": "etcd",
"EndpointID": "6c51251aa445ad221d2635cbcaed574b64f118c475985a4a63fc2323ab39b16b",
"MacAddress": "02:42:0a:00:07:02",
"IPv4Address": "10.0.7.2/24",
"IPv6Address": ""
}
},
"Options": {
"com.docker.network.bridge.default_bridge": "true",
"com.docker.network.bridge.enable_icc": "true",
"com.docker.network.bridge.enable_ip_masquerade": "true",
"com.docker.network.bridge.host_binding_ipv4": "0.0.0.0",
"com.docker.network.bridge.name": "docker0",
"com.docker.network.driver.mtu": "1472"
},
"Labels": {}
}
]Flannel验证
服务的验证比较简单,在某一个Host上运行一个容器,然后在容器中ping另一台Host的IP及虚拟的docker子网网关,如果能通则说明网络正确,具体操作如下:
c3po
[root@c3po ~]# docker run -i -t ubuntu /bin/bash
#go into the container and install iputils-ping & iproute
root@bbe3260749ad:~# apt-get install iproute
root@bbe3260749ad:~# apt-get install iputils-ping
root@bbe3260749ad:~# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
46: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1472 qdisc noqueue state UP group default
link/ether 02:42:0a:00:3e:03 brd ff:ff:ff:ff:ff:ff
inet 10.0.62.3/24 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::42:aff:fe00:3e03/64 scope link
valid_lft forever preferred_lft forever
# ping another host
root@bbe3260749ad:~# ping -w 4 10.0.63.202
PING 10.0.63.202 (10.0.63.202) 56(84) bytes of data.
64 bytes from 10.0.63.202: icmp_seq=1 ttl=63 time=0.296 ms
64 bytes from 10.0.63.202: icmp_seq=2 ttl=63 time=0.246 ms
64 bytes from 10.0.63.202: icmp_seq=3 ttl=63 time=0.217 ms
64 bytes from 10.0.63.202: icmp_seq=4 ttl=63 time=0.212 ms
--- 10.0.63.202 ping statistics ---
5 packets transmitted, 4 received, 20% packet loss, time 3999ms
rtt min/avg/max/mdev = 0.212/0.242/0.296/0.038 ms
# ping another host's docker gateway
root@bbe3260749ad:~# ping -w 4 10.0.7.1
PING 10.0.7.1 (10.0.7.1) 56(84) bytes of data.
64 bytes from 10.0.7.1: icmp_seq=1 ttl=61 time=1.30 ms
64 bytes from 10.0.7.1: icmp_seq=2 ttl=61 time=0.448 ms
64 bytes from 10.0.7.1: icmp_seq=3 ttl=61 time=0.426 ms
64 bytes from 10.0.7.1: icmp_seq=4 ttl=61 time=0.396 ms
--- 10.0.7.1 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3001ms
rtt min/avg/max/mdev = 0.396/0.644/1.307/0.383 ms从结果可以看出,flanneld的扁平网络可正常工作。
另外,CentOS自身的源已经包含Kubernetes包,并且应该是经过大量测试的,因此推荐使用yum直接进行安装,并使用systemd进行启动。
推荐两篇部署文档: